占用率 (Occupancy)
占用率表示GPU正在运行的线程块和理论上能运行的最大线程块数量的比值。它可以反映GPU在给定时间点上背有效利用的程度。GPU占用率公式: \[ Occupancy = \frac{Active \ warps}{Max \ warps\ per \ SM} \] GPU的占用率被每一个thread block使用的资源量制约。制约的资源包括:寄存器数量,共享内存,Block 大小,和其支持最大并发线程数,分支与同步。
寄存器数量限制:
假设设备的 registers / SM 是 32k,最大支持 1536 threads / SM - 即最大支持48个warp。
若每个 thread 用63个寄存器,那么 32k / 64 = 512 threads。Occupancy: 512 / 15366 =0.0333
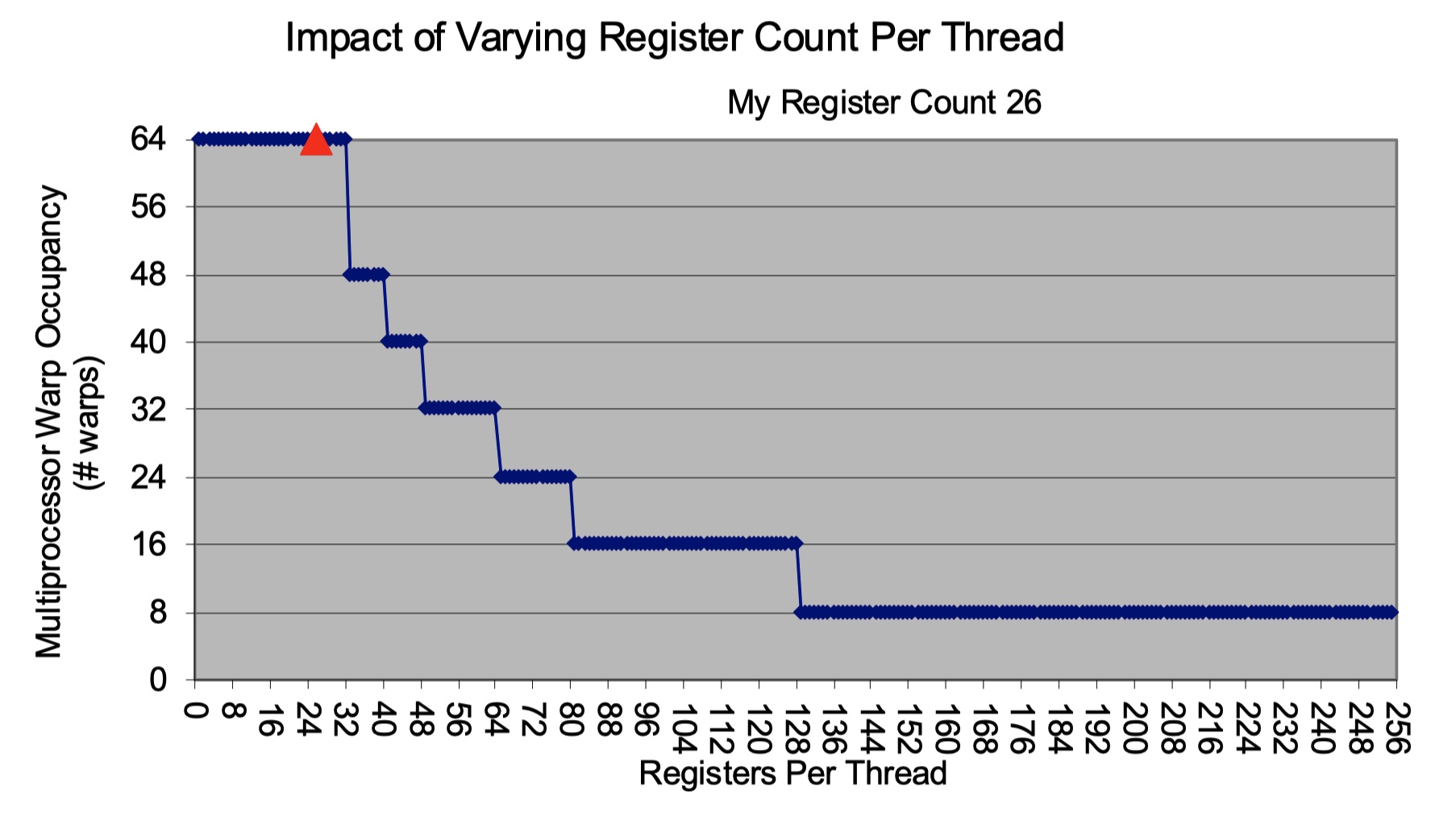
当register / thread 增大,occupancy阶梯式会下降。阶梯式是因为SM是以warp为单位执行的。当register多到需要去除掉一个active warp时才会下降。
共享内存限制:
假设设备的 shared memory 是 48kb
若每个 thread 使用 64b 的共享内存,那么一共支持 48k / 64 =768 个线程。Occupancy: 768 / 1536 = 0.5
Block size 限制:
假如设备每个SM最多能放8个block,如果block小,那么SM就无法包含足够的warp。
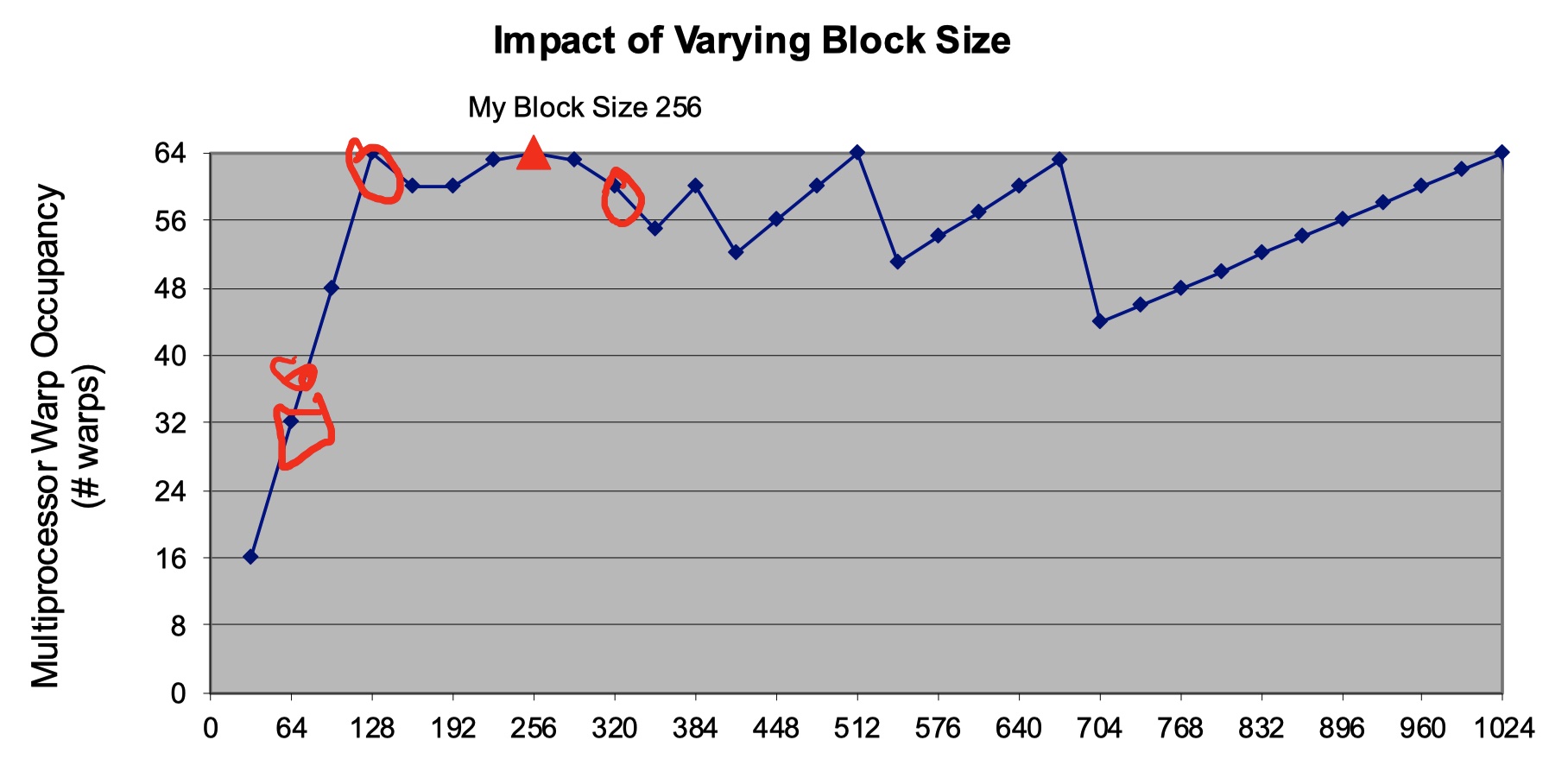
一开始时递增是因为block太小,warp不够多。在 \(block = 128\) 时warp达到最大,然后进入波动。波动的原因也是因为block size 内剩余的thread不足以构成一个warp。不同block的thread又无法组成新warp,因此会浪费掉一些占用率。
优化思路:
高占有率并不代表高性能,根据 Vasily Volkov 的研究,达到期待性能所需要的GPU性能所需占用率与计算强度有关。
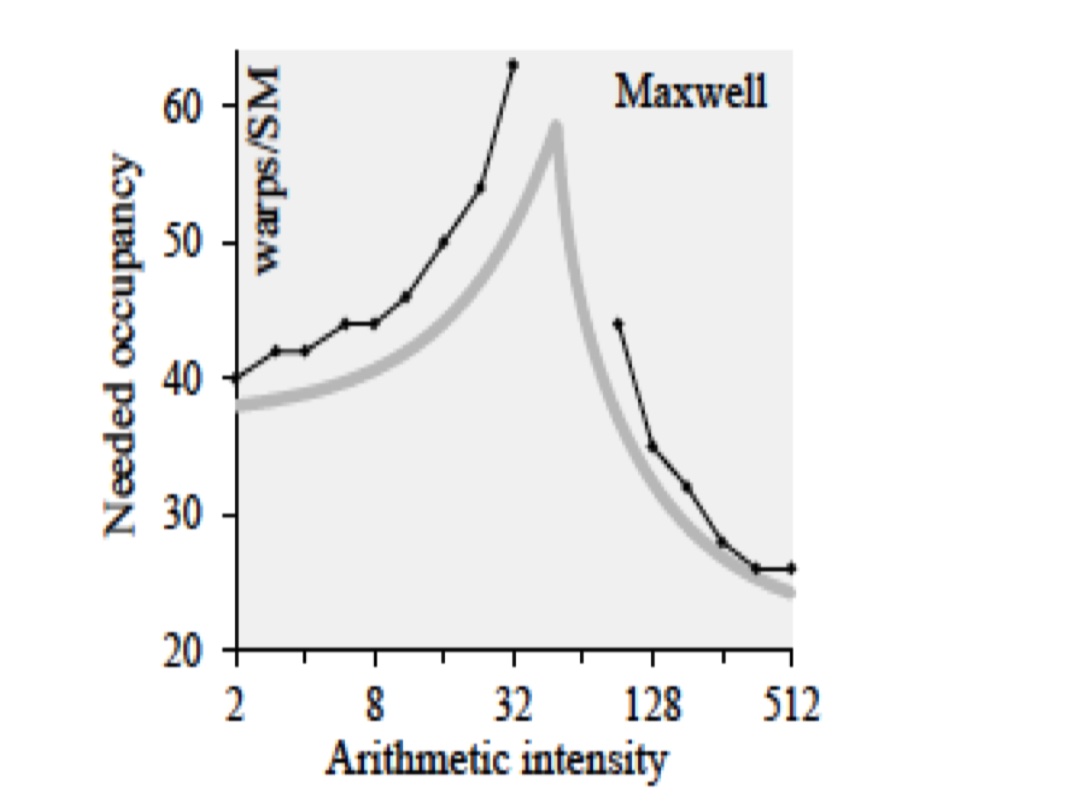
当计算强度低时,内存延迟成为主要瓶颈,需要更高的GPU占用率来隐藏延迟。(有更多的warp来切换)
当计算强度高时,GPU计算单元充分利用,不需要频繁切换warp,需要考虑优化指令效率等
低占用率过低可能是优化机会,可以调大线程块大小,减少单线程对寄存器和共享内存的使用。
Little's Law in GPU
在GPU中我们也可以算出想要保持硬件满负载,SM要同时处理多少个warp的指令。例如:kepler有192个核心,1个warp执行一个指令要做32个操作。
- 那么每个cycle,SM可以同时处理 \(192 / 32 = 6\) 个warps。假设每个instruction有9个cycle的延迟,那么想要保持硬件满负载我们需要 \(9 \times 6 = 54\) 个warps。
这里我们也可以计算出内存操作需要多少并发度来隐藏延迟。若有一个机器,访问内存的延迟为 386 cycles,一共16个SM,每一次load会合并128B的数据传回,带宽为211GB/sec,机器的频率时1.266GHz。
- 那么每个cycle,可以从内存里传输来的数据为 \(211 / 1.266 =166.67B\) 。由于每次load instruction可以传回\(128B\)的数据,那么设备的吞吐量为 \(166.67 / 128 = 1.30 \text{ instructions per cycle}\)。由于我们有16个SM,每一个SM的吞吐量为 \(1.3 / 16 = 0.081\)。那么我们每一个SM需要的并行指令数为 \(386\times 0.081 = 32 \ (取整)\),也就是说我们需要32个warps。
Thread Level Parallelism & Instruction Level Parallelism
目标:隐藏延迟 & 提高吞吐量
- Thread Level Parallelism (TLP): 通过增加warps的数量,在等待延迟时切换到其他线程执行任务
- Instruction Level Parallelism (ILP): 在同一个线程中发出多个相互独立的指令,在等待指令结果时运行其他指令
例如 Kepler GPU 就可以每个时钟发射两个命令。单这两个命令不能有依赖,否则将会有延迟。我们可以通过引入更多的独立指令来提高指令并行度,更好的利用GPU执行单元。
我们通常会增加TLP来追求更好的性能,然而增加TLP有一定的局限性。
- 寄存器和共享内存这种硬件资源限制了TLP增大
- 当问题规模本身比较小,我们无法分配足够多线程块,导致TLP无法提高
- 内存访问模式 (无法coaleasing) 成为瓶颈,所有的thread都在load
- 线程之间存在依赖
TLP 和 ILP 可以互补:
- 当TLP高,但未饱和,继续增加warp已经没有效果了,这时可以使用 ILP 来增加但线程效率,正价吞吐量。
- 当TLP低且受到资源限制时,硬件利用率低,可以通过增加ILP来填满硬件单元,提高吞吐量。
- 当内存延迟高,我们可以通过TLP线程切换来隐藏延迟。
Performance Prediction
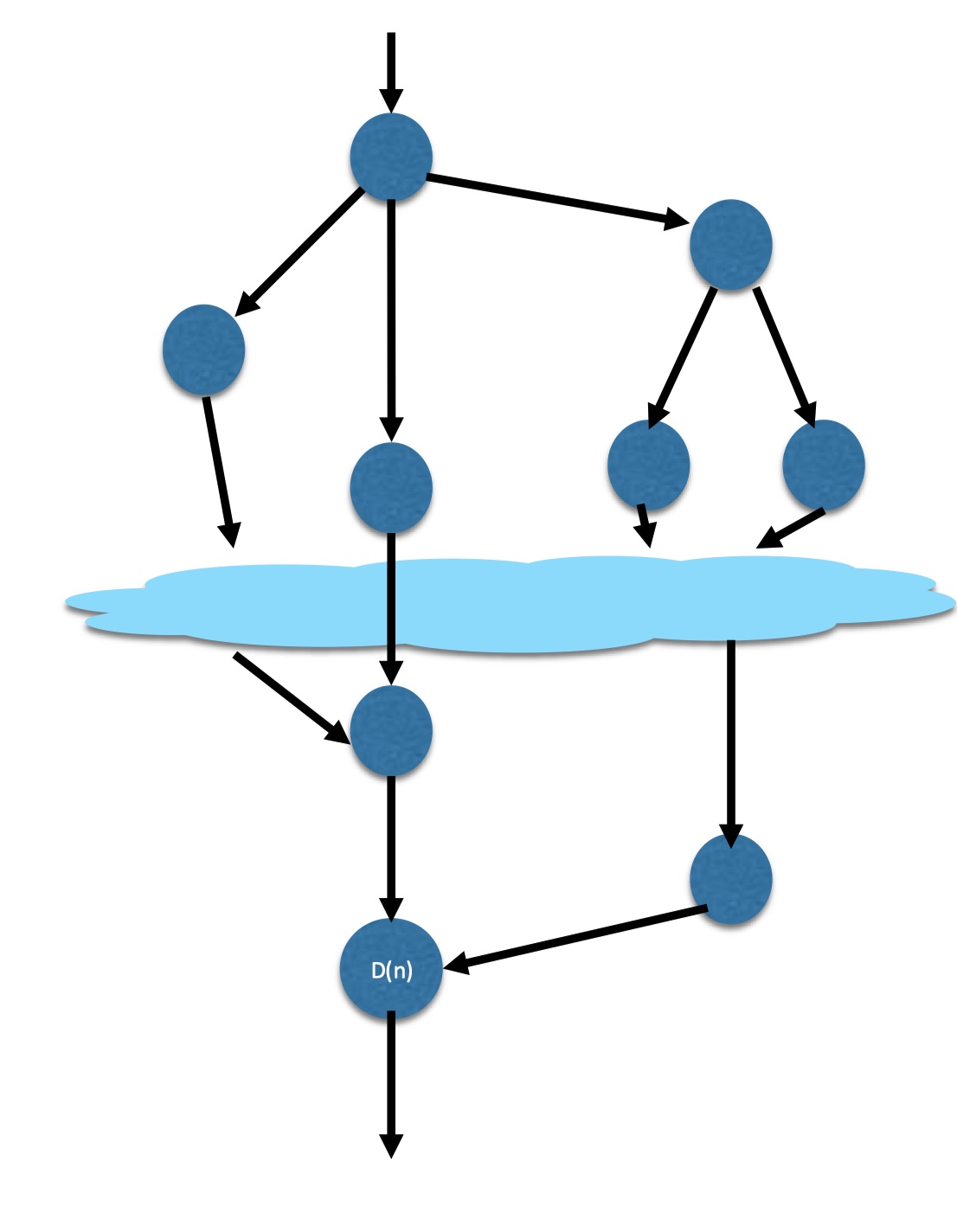
总共的工作节点用时: \(W(n)\)
最长路径上的工作节点用时:\(D(n)\)
工作用时:\(T_{comp} = D(n) + \frac{W(n) - D(n)}{p}\)
p 是处理器数量
\(W(n) / D(n)\) 越大表示并行度越高
Reference
Vasily Volkov, “Understaning Latency Hiding on CPUs”, PhD Thesis, University of California, Berkeley, Summer 2016