GPU 存储空间架构
粗略内存架构图:
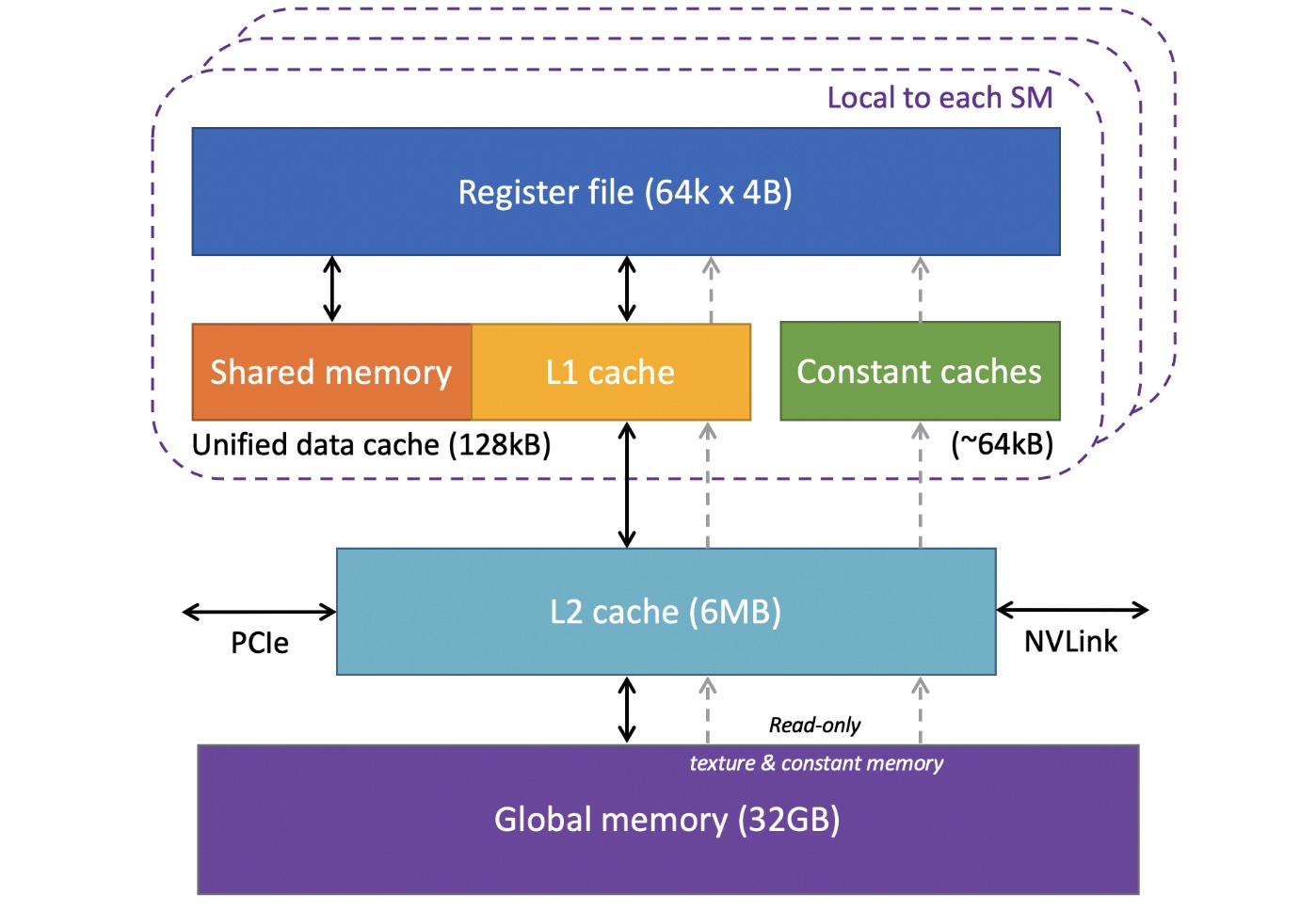
内存被粗略的分为全局内存,L2缓存,L1缓存,共享内存,和寄存器文件这几层。全局内存最大但离CUDA核心最远。
缓存行被设计为 \(128 = 4 \times 32\) 个字节。由于32个id连续的线程是一个warp,一个warp执行相同的代码,因此访问操作一般是将数据传输给warp里每一个thread的。如果warp所有线程访问数据都集中在同一缓存行上,能充分利用带宽,避免浪费。
每个SM的寄存器文件被设计成"多行32列"。这是因为每个warp共有32个thread,而每个thread又使用同一个程序,也就是说在任意时间段,他们使用的寄存器都一摸一样 (即便有分枝,也知识一些线程空闲,继续其他代码操作)。因此,一个warp在执行的每个时刻会访问寄存器文件的同一行。一个程序会使用多少个寄存器会在编译时计算出来,用于warp寄存器分配。当算出需要的寄存器数量,warp会被分配多行寄存器。如果有多个warp,多个warp可以被分配到不同范围的行,从而并行执行 (可跨行分配)。当寄存器不足,会发生寄存器溢出 (register spilling),数据会被临时存储到 L1 缓存,导致性能下降。
Shared memory 和 L1
缓存是基于bank模型设计的。Bank模型是为了让缓存的访存并行化。通常缓存被分为32个bank,与一个warp有32个thread相对应,并通过
address % bank_number
映射到对应的bank。如果一个warp内的个线程同时访存一个缓存的两个属于不同bank的数据,那么这两个线程可以并行进行访存操作。
共享内存和 L1 缓存共享物理空间,但允许线程块内的线程共享数据。常量缓存用于只读的全局变量,主要用于在warp中广播单一变量值。L2缓存是设备唯一的全局缓存,用于SM与主存之间的数据交互,同时介导设备和主机的数据传输 (使用 PCIe 或 NVlink)。
精细内存架构图:
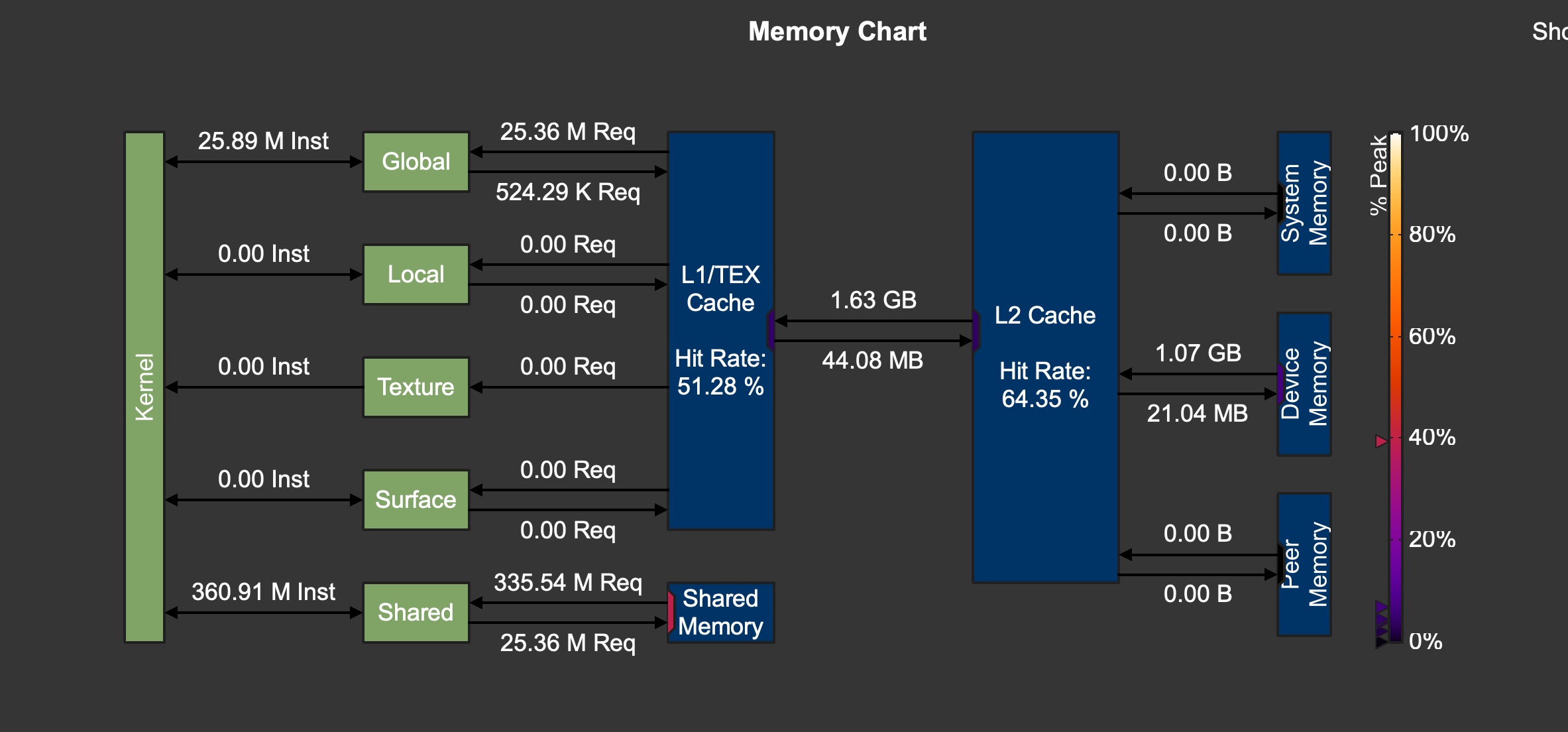
L1缓存实际被分为了:
- Global:缓存全局内存数据,提升全局内存的读取效率
- Local:处理寄存器溢出的本地内存数据 (局部变量)
- Texture, Surface: 缓存纹理 & 表面数据,支持read only操作,特定图形操作
GPU之间的数据传播 & 主机到设备的数据传播都会先经过 L2 缓存,这里 L2 缓存起到了缓冲的作用,减轻了device memory的压力。
GPU 线程架构
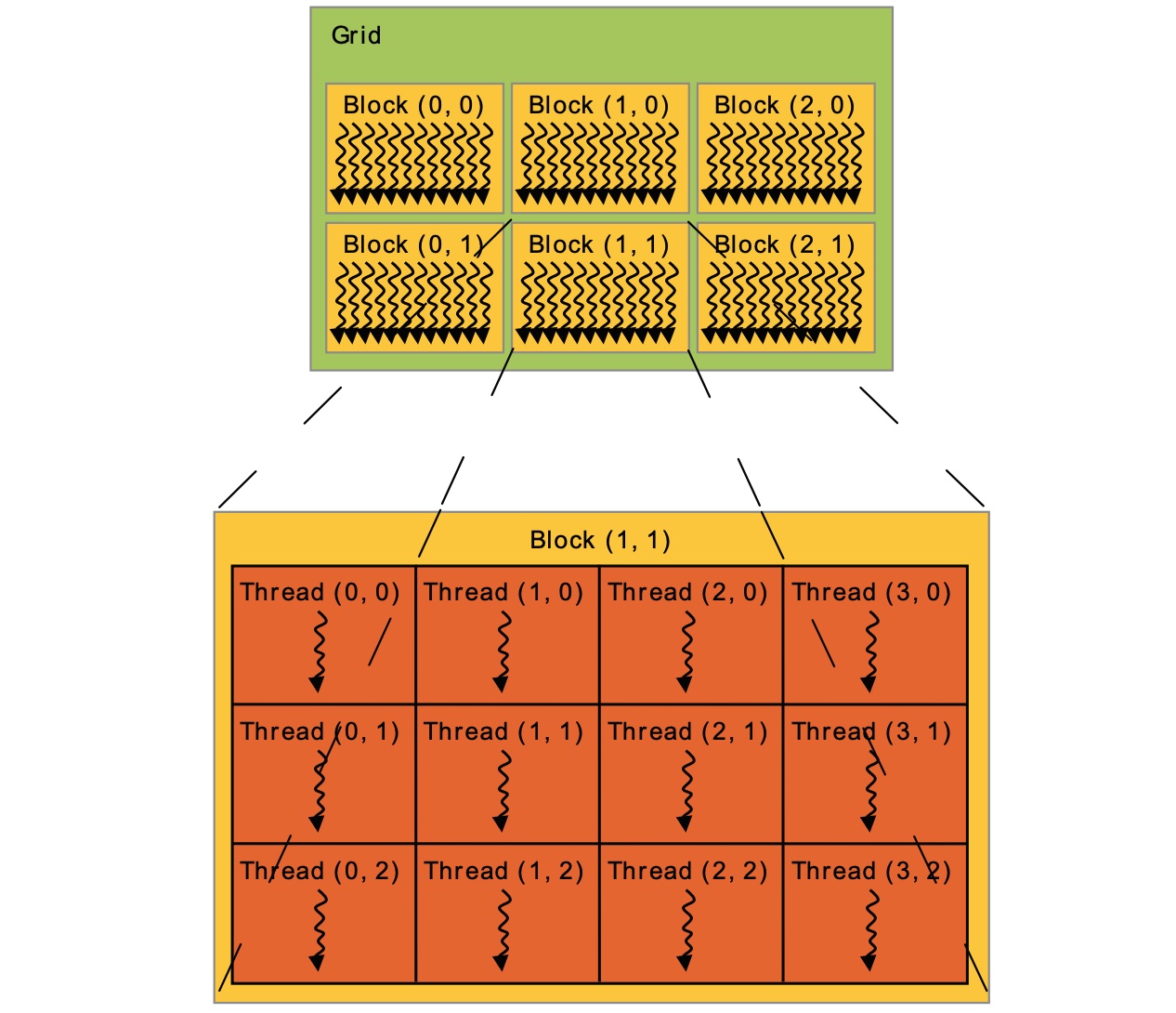
在程序中,线程架构由 Grid,Block, 和 thread 构成。
计算 local thread ID :
1 | threadId.x + threadId.y * blockDim.x + threadId.z * blockDim.x * blockDim.y |
计算 global block ID:
1 | blockId.x + blockId.y * blockDim.x + blockId.z * blockDim.x * blockDim.y |
程序执行时会在启动每一个并行内核时创建一个grid (根据代码中声明的参数)
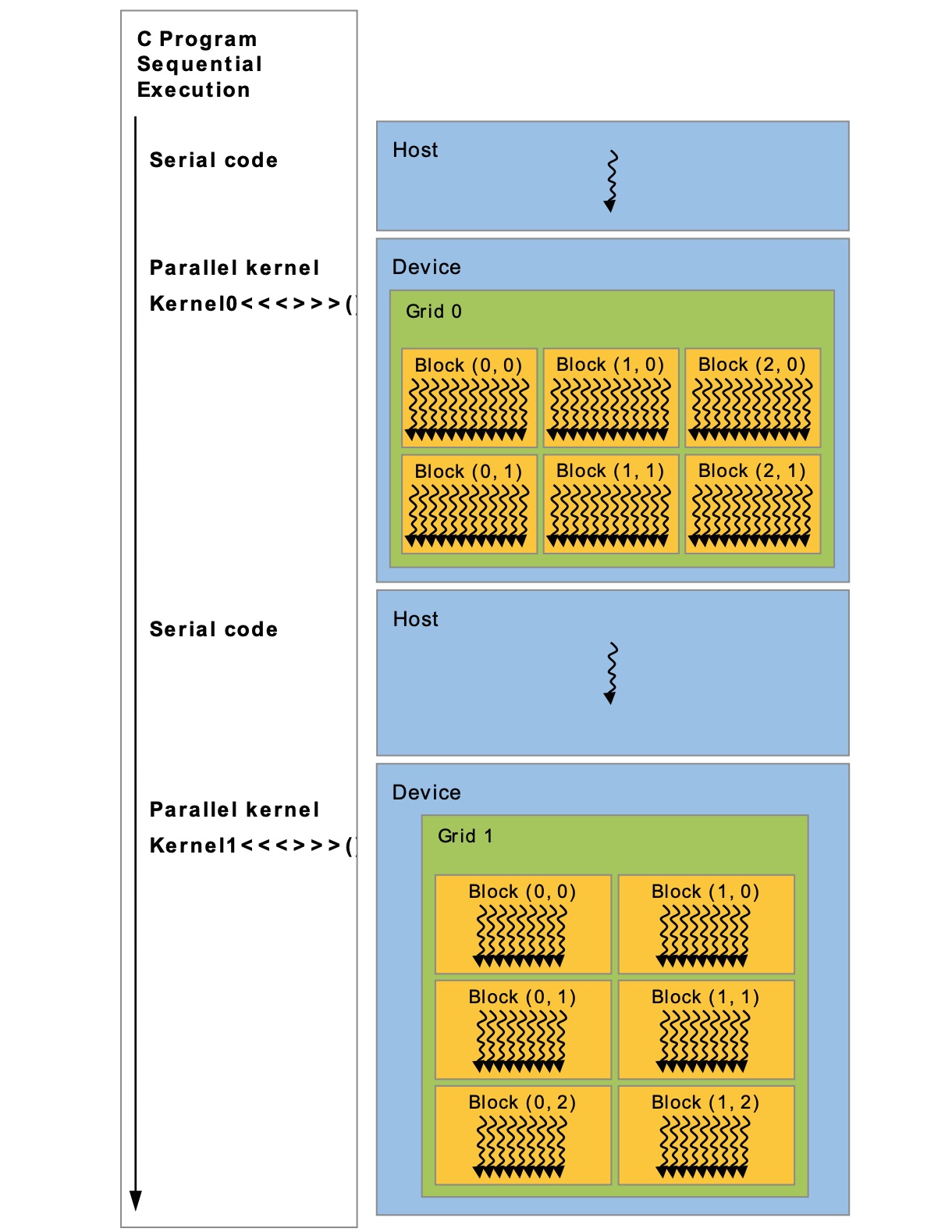
一个 grid 会被提交到一个设备上,一个设备上会有多个 Streaming Multiprocessors (SMs)。grid 上的 block 会被分配到不同的 SM 中,这里会根据 SM 负载压力调度。
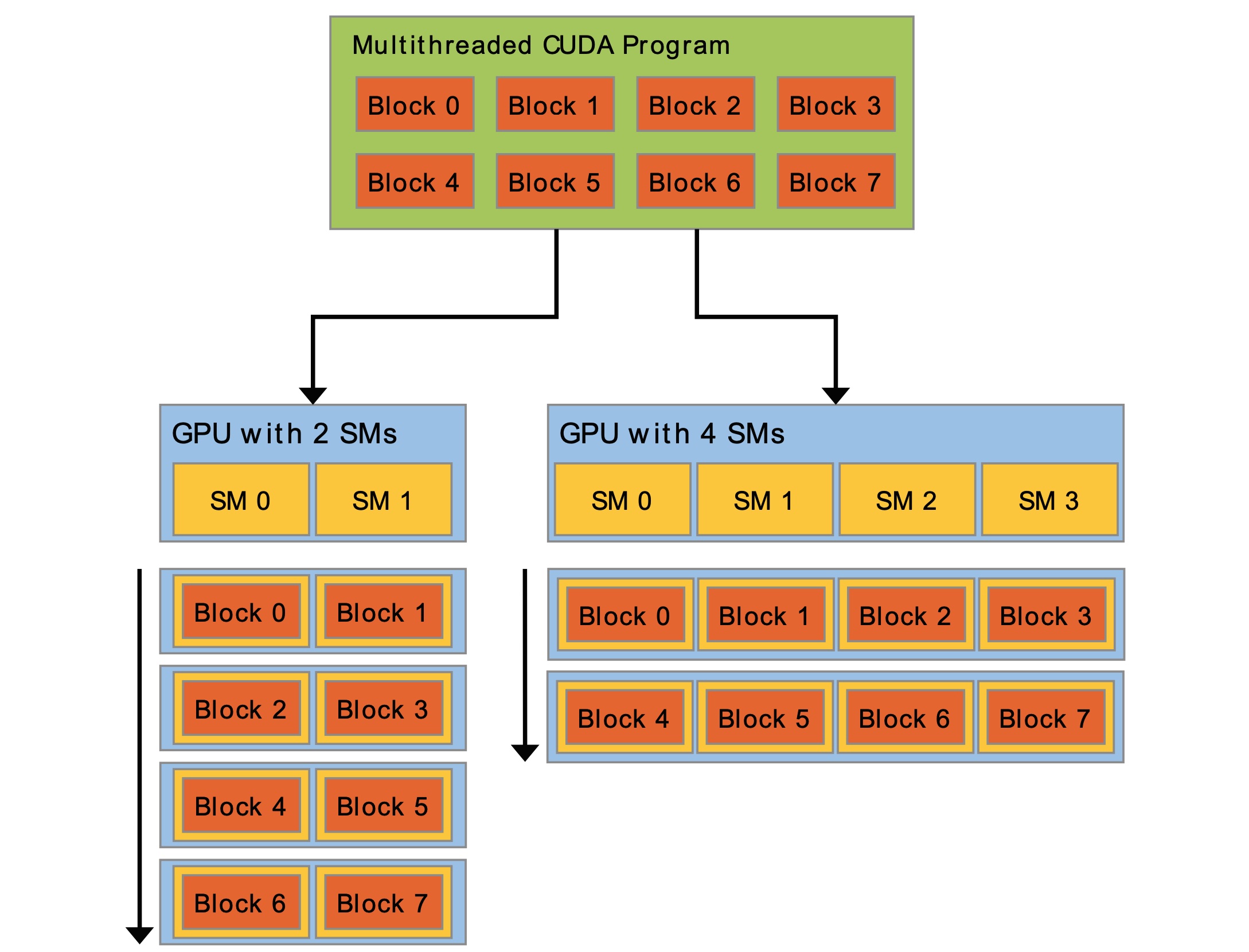
硬件发展角度:Warp 及其调度
一个warp是由32个并行线程组成的线程组。这个线程组是通过划分block得来,每个warp包含连续的线程ID,从0开始划分。不同的warp间执行时独立的。在一个SM中可以存在多个warp,如果一个warp的输入操作数没有加载好,warp
schedular可以切换到其他加载好的warp执行,或者是不依赖的指令执行。这里依赖编译器进行
read after write 错误,比如 fadd r4 r4 1
要用9个cycle,那么编译器不会在9个cycle调用任何使用r4的指令。
划分warp的目的时为了简化硬件设计,提高并行计算效率。Warp 时基于 SIMT (Single Instruction Multiple Threads) 架构的,结合了 SIMD 的高效性和 TLP 的灵活性。Warp 级调度可以在不同warp间无成本切换,支持高效硬件多线程。
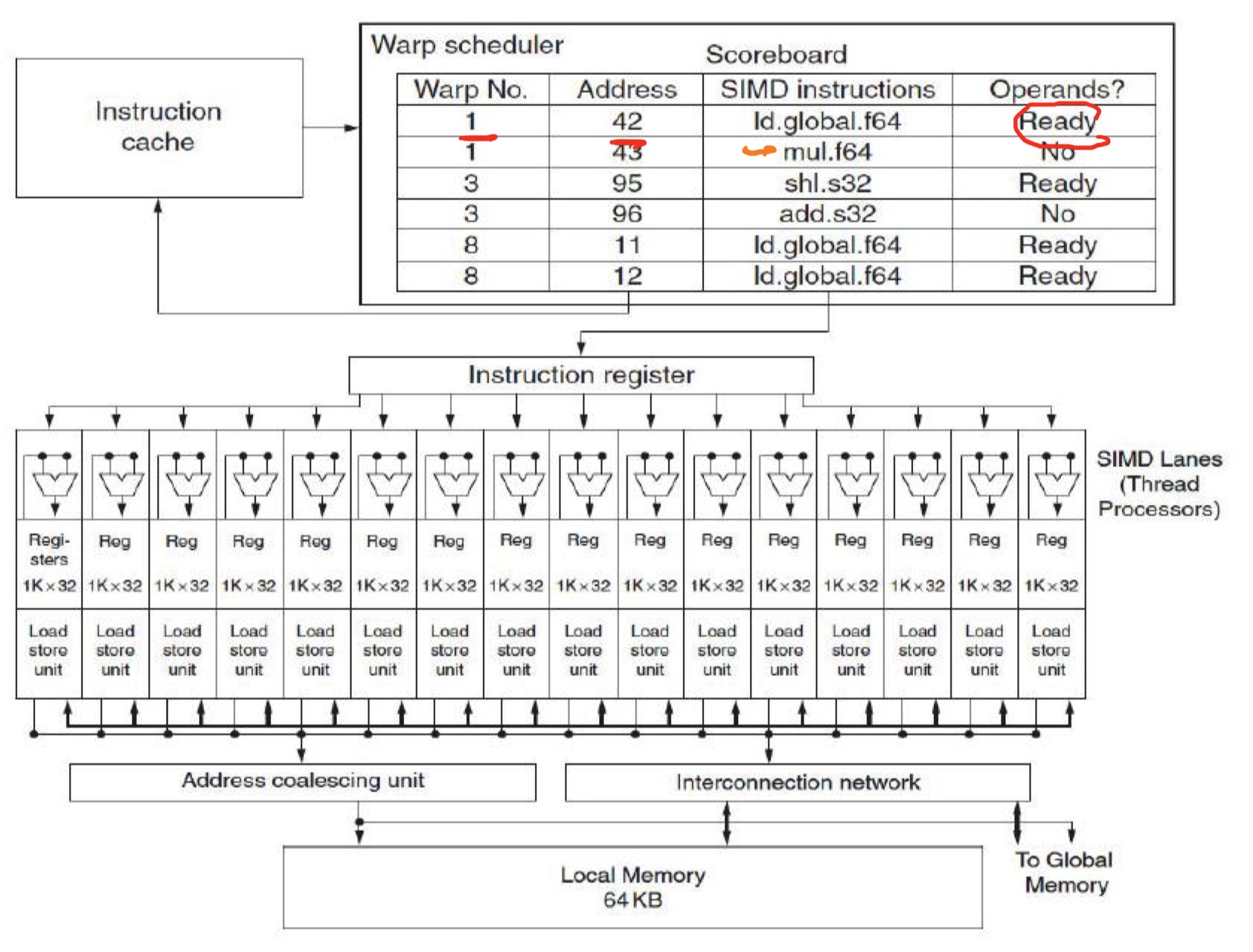
Warp scheduler 维护了一个 scoreboard,用来跟踪该SM中的warp的操作数准备状态。不同block但属于同一个SM的warps 也可以调度。
Volta架构之前:
我们可以假设warp内线程总是同步的,在发生分支发散时,线程会通过屏蔽非活动线程将不同的分支串行处理,简化了控制逻辑。但代价是分支发散的性能很低,我们需要尽可能避免写分支发散的代码。当然,如果分支赋予了属于不同warp的线程不同的任务是没问题的,因为只有属于一个warp的线程需要执行相同的代码。
Volta架构之后:
每个线程拥有独立的程序计数器和调用栈。Warp 调度器可以在更细的粒度调度线程,不再局限于warp级别。更灵活的线程调度允许warp调度器在内存访问延迟,寄存器依赖等情况下充分利用计算资源,从而减小延迟对性能的影响。
编译:PTX 与 PTXAS
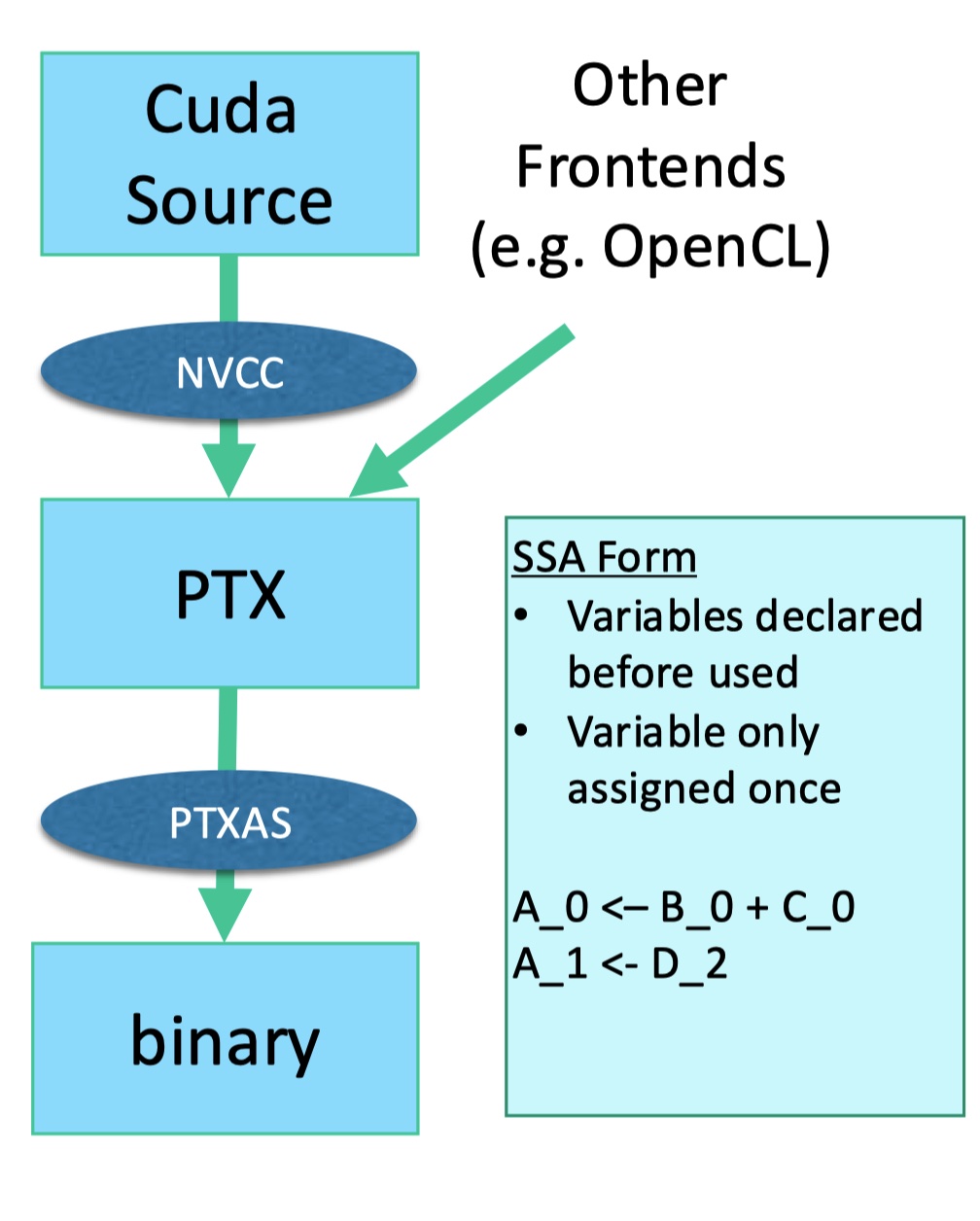
CUDA源码会先经过nvcc编译成PTX,PTX时不依赖于特定GPU的,然后在用设备特定的 PTXAS backend compiler 将PTX做物理寄存器赋值。这样CUDA代码就拥有了可移植性,不再受特定设备型号限制。
PTX给所有的变量都赋予了虚拟寄存器,同时还做了predication支持,当遇到条件分支,会检测条件是否满足,若不满足,将会填充NOP。
Reference
https://docs.nvidia.com/cuda/archive/11.2.0/pdf/CUDA_C_Programming_Guide.pdf