CPU 缓存
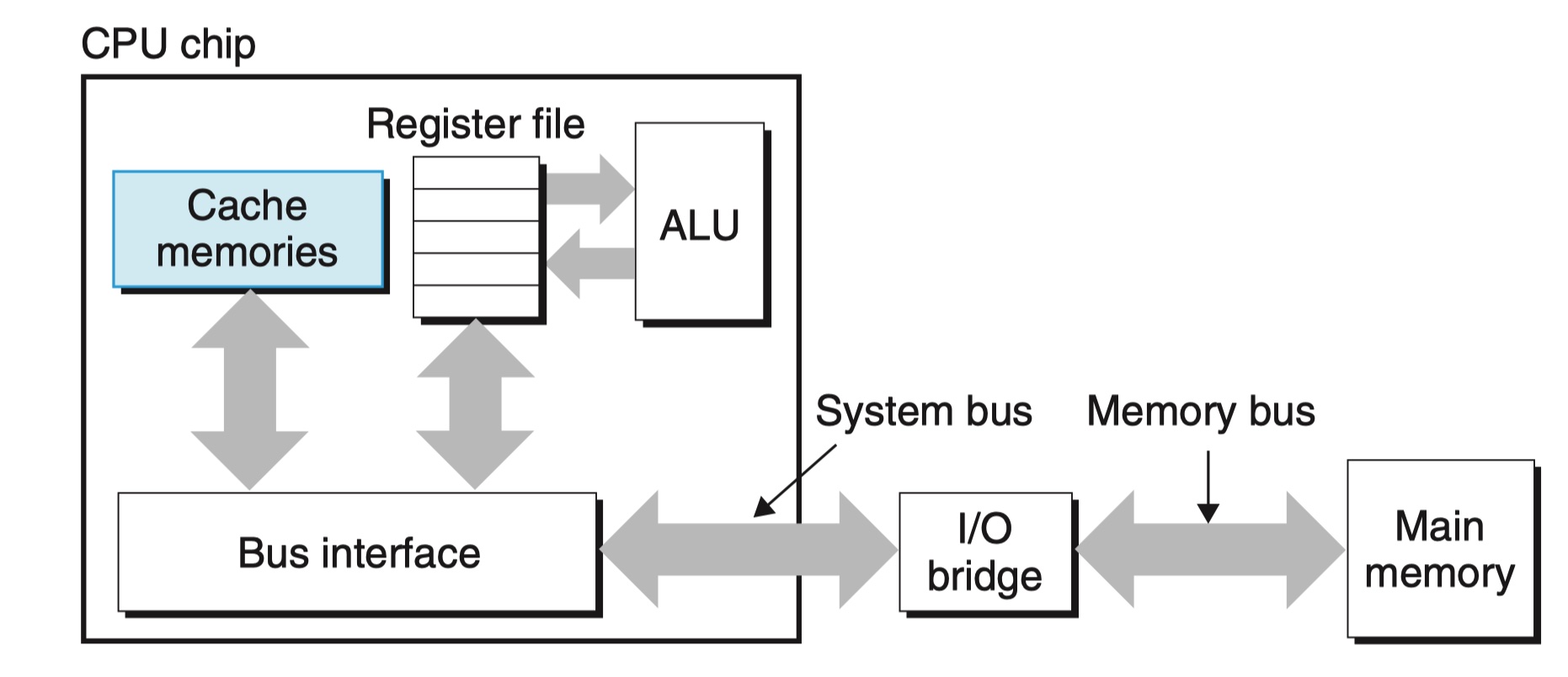
高速缓存包括:指令高速缓存 i-cache, 数据高速缓存
d-cache. 现代处理器用 i-cache 和
d-cache 替代了 unified-cache
从而方便并行读取一个指令字和一个数据字。
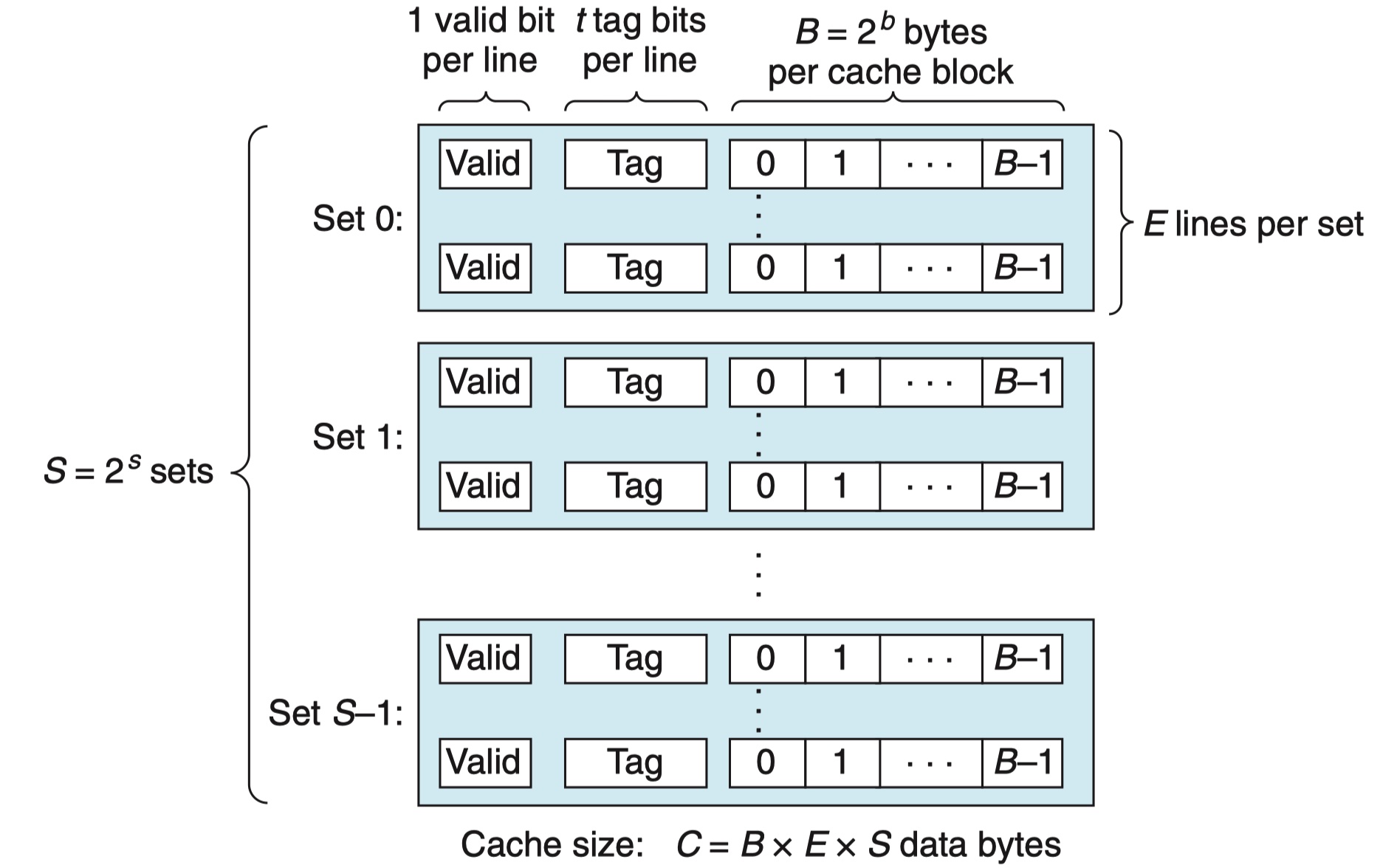
通用高速缓存存储器组织架构:
假设一个计算机的存储地址有 \(m\) 位,形成 \(M = 2^m\) 个不同的地址。这样一个机器的高速缓存被组织成一个有 \(S = 2^s\) 个高速缓存组,每个组包含 \(E\) 个高速缓存行,每个行由 \(B = 2^b\) 字节的数据块组成的存储空间。高速缓存组中的每一个高速缓存行由 \(1\) 位的 valid bit 声明是否含有有用信息,\(t\) 个不同 tag bit 用来标识每一个缓存行。
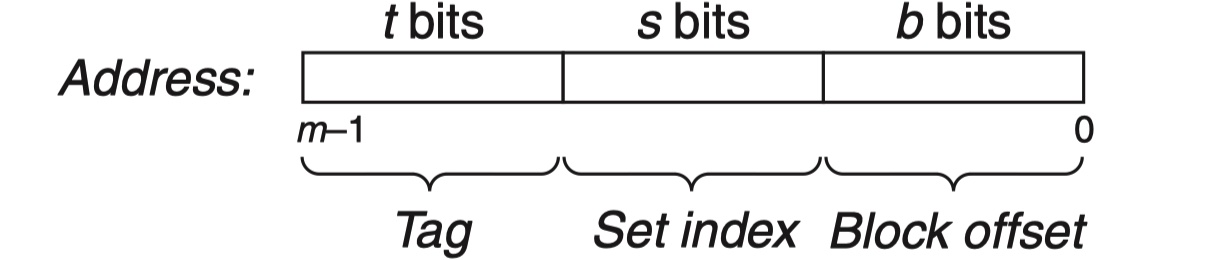
现代缓存地址会讲内存地址分解为标记位,块偏移位,和组索引位。
- 组索引位用来找到数据所在的缓存组
- 标记位告诉我们缓存组中的哪个缓存行包含了这个字,当且仅当valid位设为1,缓存行中才包含这个字
- 块偏移位给出了该数据在缓存行中的偏移
从内存地址到缓存数据查找,本质上是将大的地址范围映射到小的地址范围,共有3种映射策略:
直接映射高速缓存:
直接高速缓存就是每个缓存组中只有一个缓存行
我们只需要通过组索引找到缓存组,看valid位是否置为1,再对比tag位,若匹配,则通过块偏移找到目标数据。
缓存抖动
1
2
3for (int i = 0; i < 8; i++) {
sum += x[i] * y[i]; // 当 x[i]和 y[i]映射到相同的缓存组
}这里因为缓存组里只有一个缓存行,高速缓存会反复加载和驱逐相同缓存组的缓存行
组相连高速缓存:
映射过程就是上述通用高速缓存映射过程
不命中替换:
- 最近最少使用:Least-Recently-Used (LRU)
- 最不常使用:Least-Frequently-Used (LFU)
替换都需要额外的时间和硬件
全相连高速缓存:
- 全相连高速缓存就是一个包含所有高速缓存行的高速缓存组
- 映射时地址不划分组索引位,地址只被划分为一个tag和块偏移,从这一唯一的组中寻找数据与其他映射一致
局部性 (Locality):
- 时间局部性 (Temporal): 最近使用的数据会再次使用
- 空间局部性 (Spatial): 与过去使用过的数据内存相邻的数据会在不远的未来被使用
3种 Cache Misses:
- Cold Miss: 当我们第一次使用这个数据
- Capacity Miss: 缓存的空间不足
- Conflict Miss: 缓存空间足够,但有太多的数据被映射到了相同的的缓存集,导致被替换
CPU指令流水线
这里我们通过 Loop Unroll 让
现代高性能CPU分支预测
分支预测发展历史:
Reference
CSAPP
https://blog.eastonman.com/blog/2023/12/modern-branch-prediction-from-academy-to-industry/