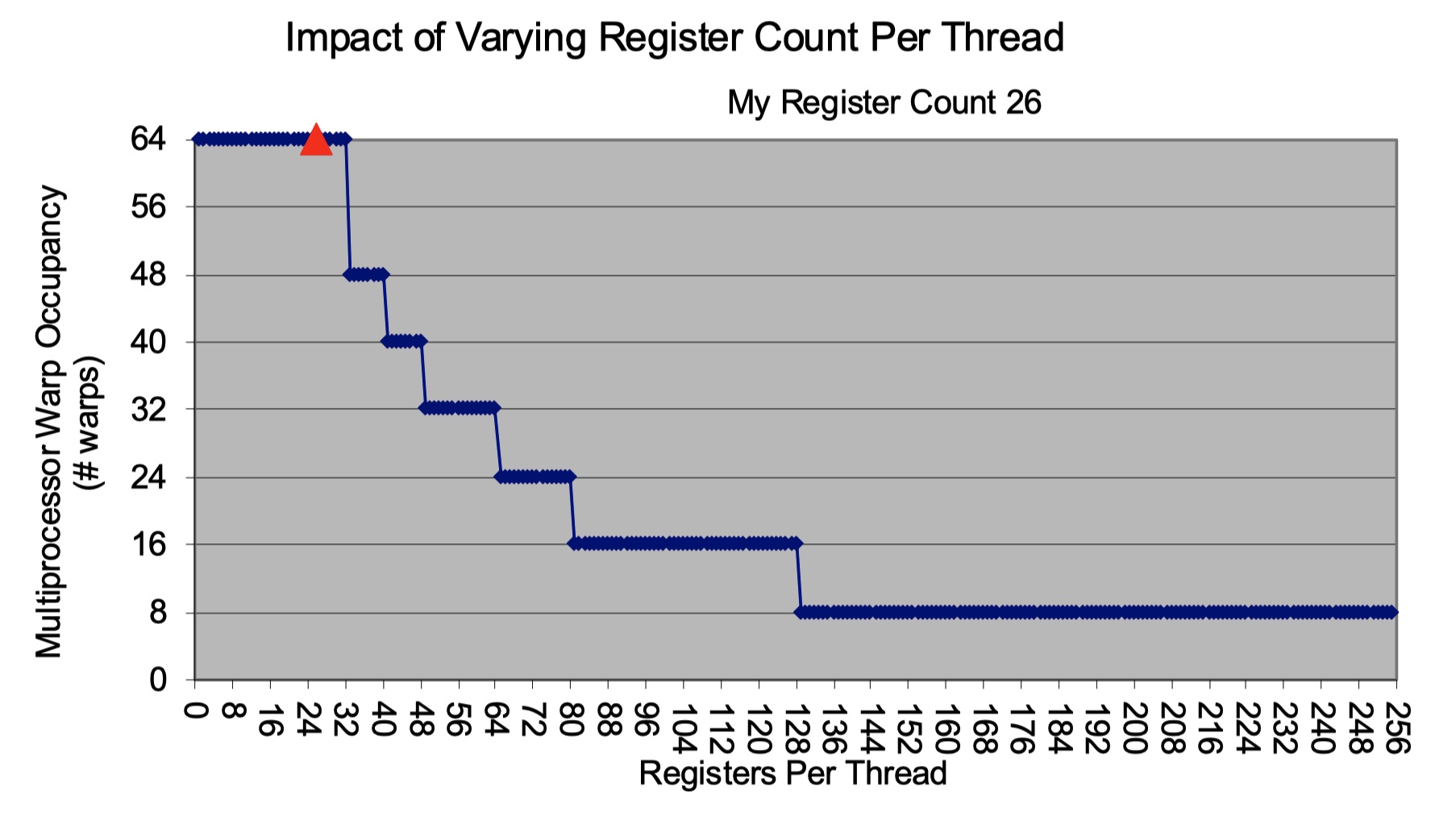
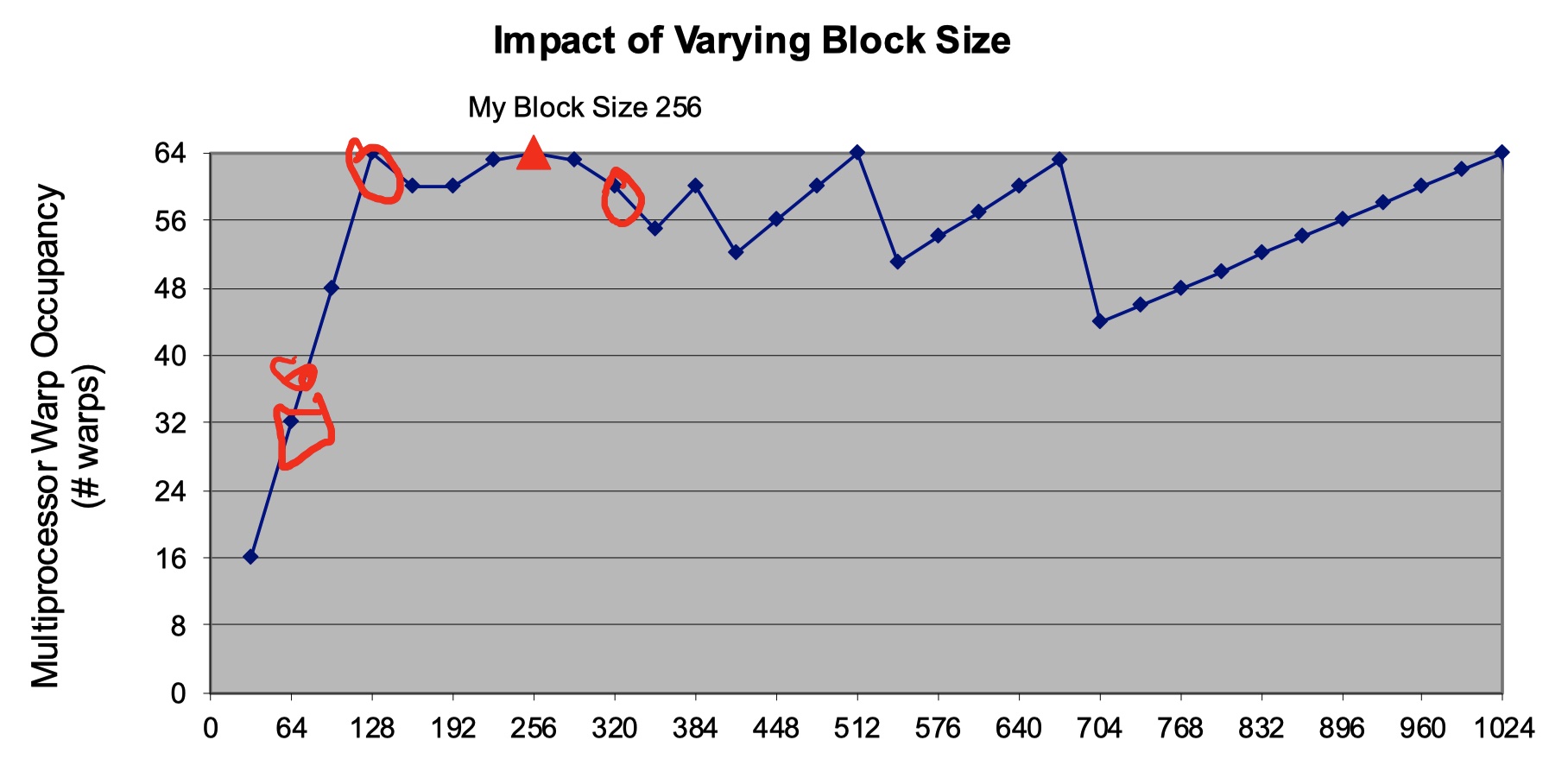
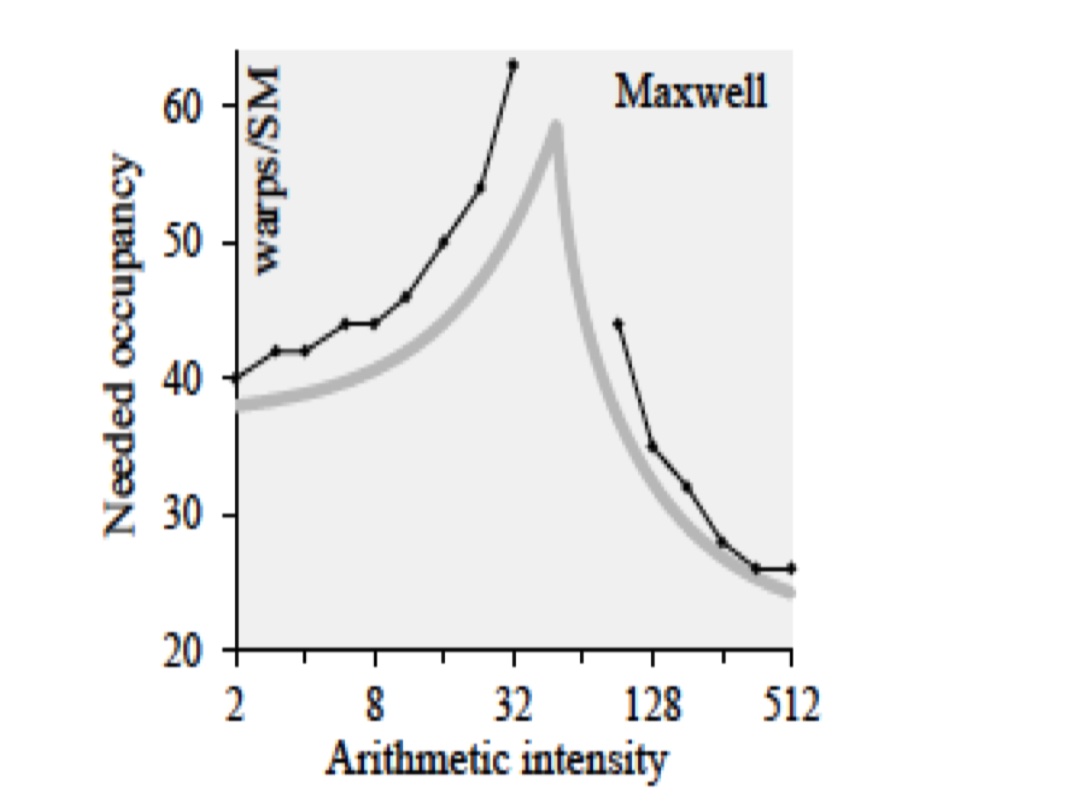
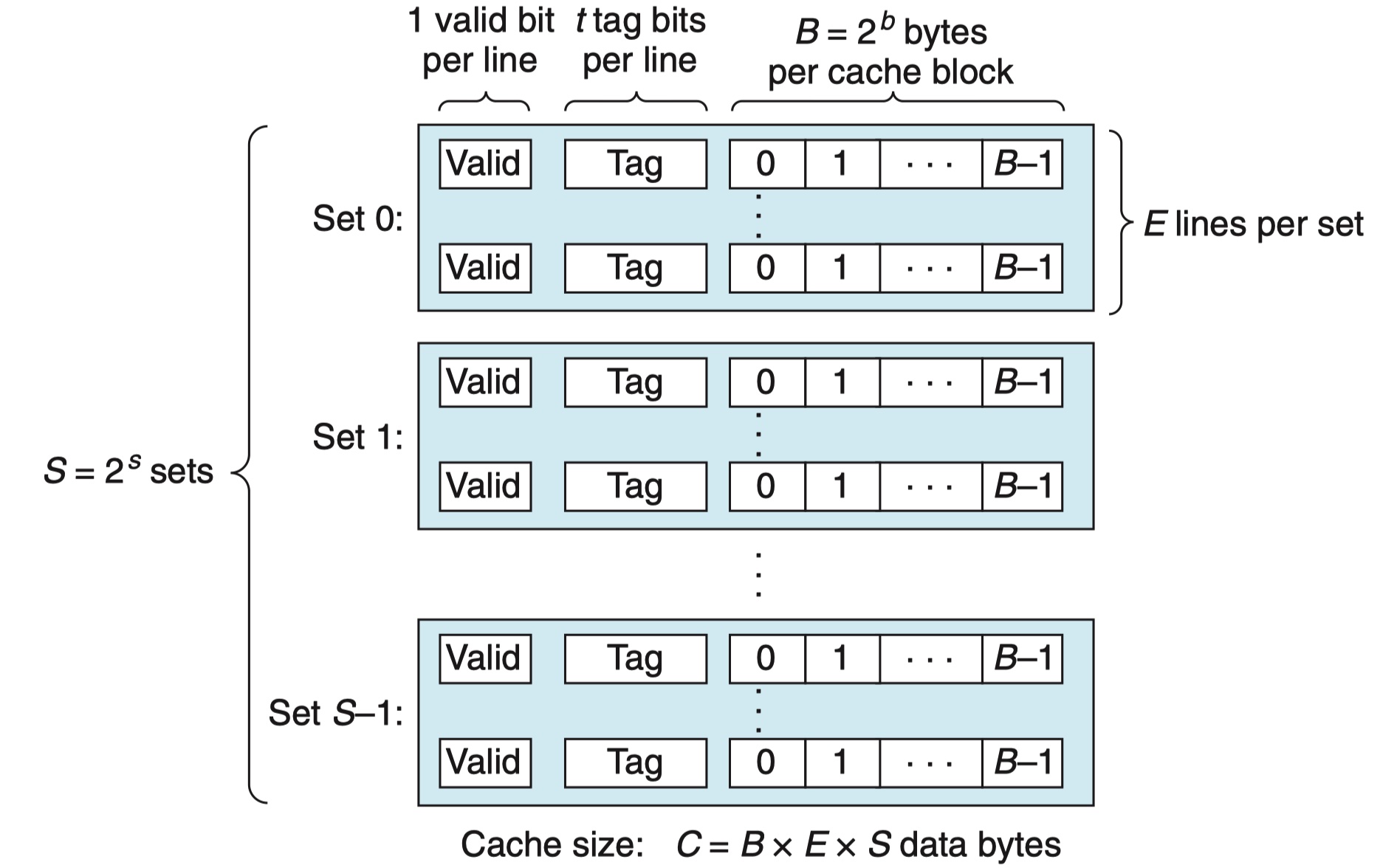
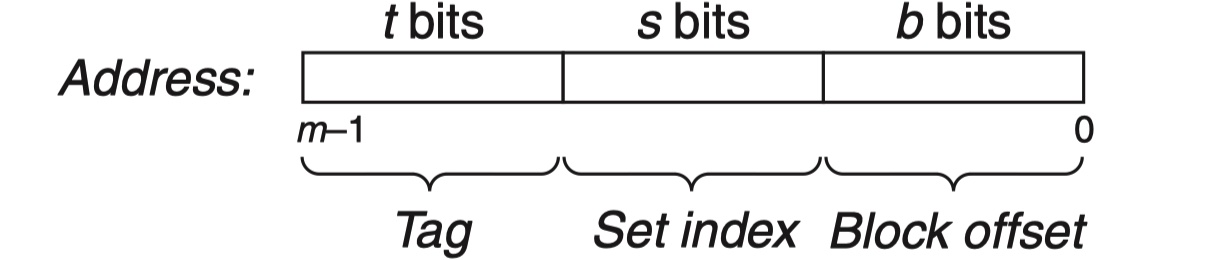
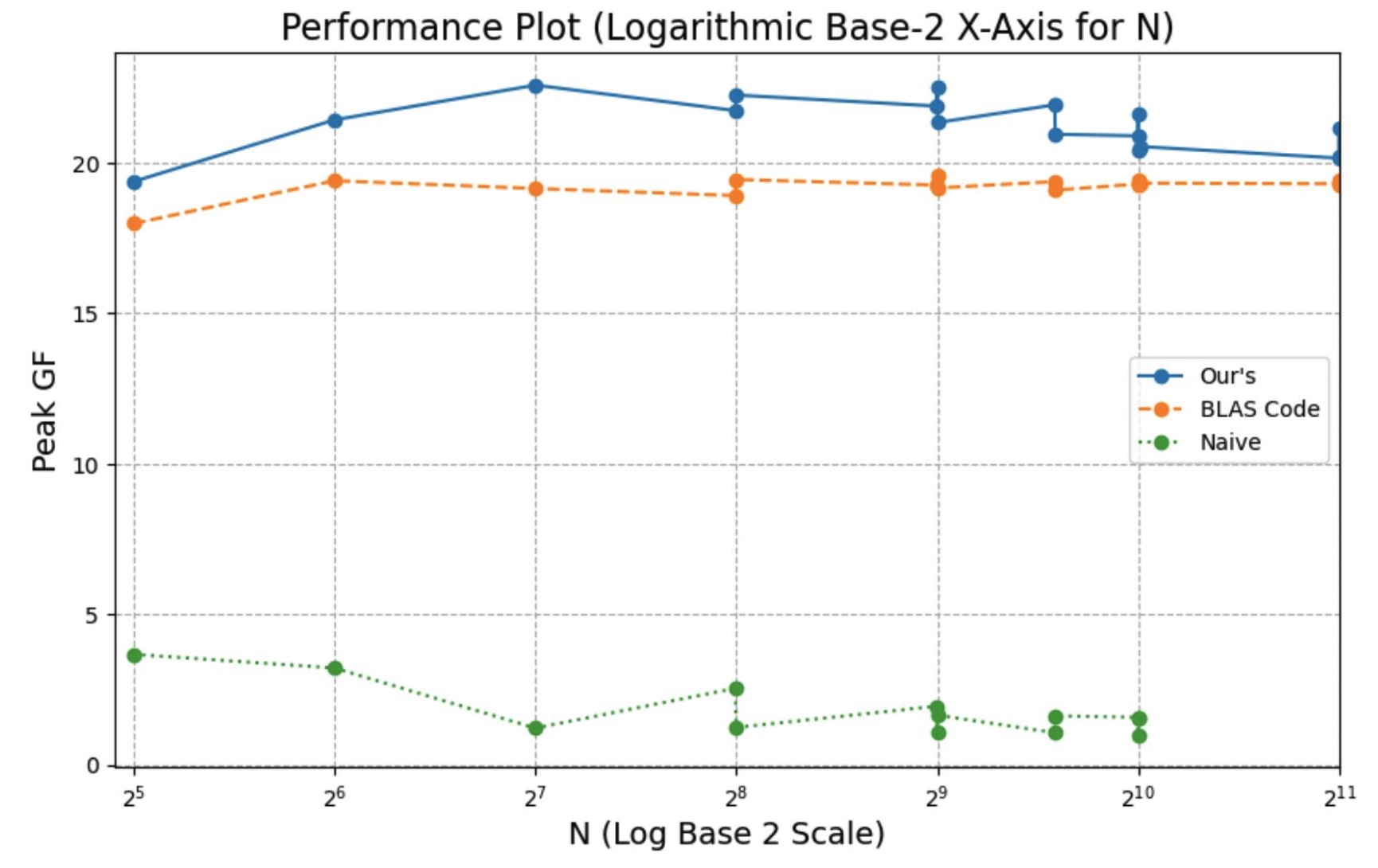
实验设备:AWS c7g.medium
Result:
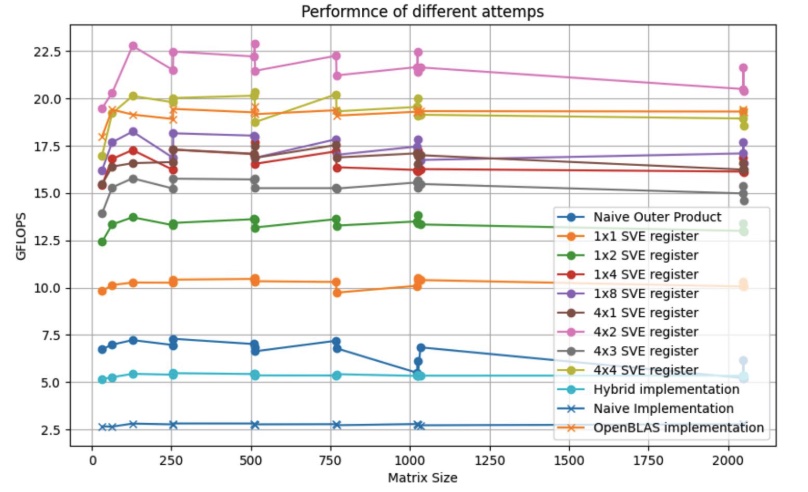
能跑赢 OpenBLAS (单核中)
Naive GEMM
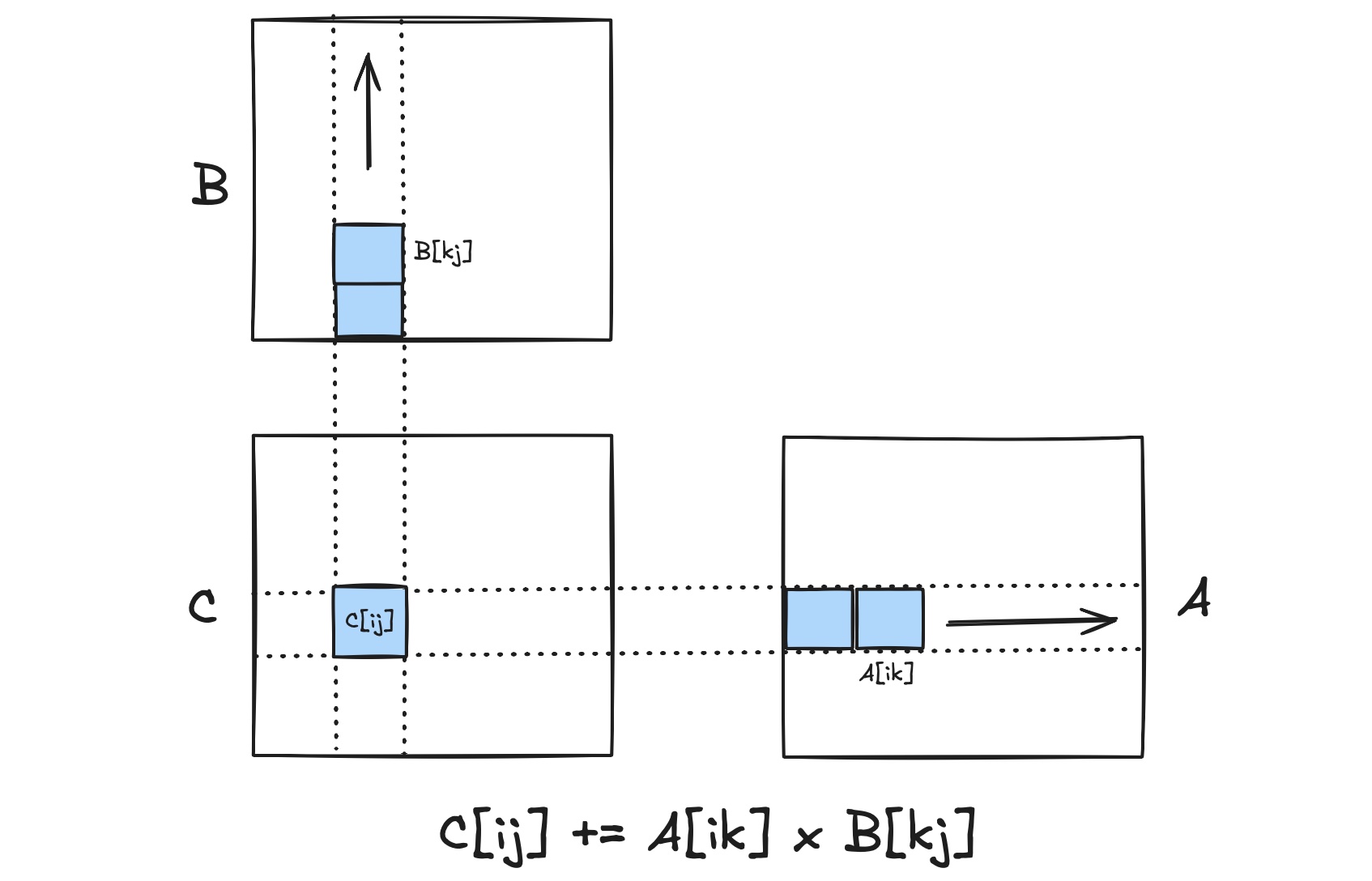
1 2 3 4 5 6 7 8 9 10 for (int i = 0 ; i < N; i++) { for (int j = 0 ; j < N; j++) { for (int k = 0 ; k < N; k++) { C[i][j] += A[i][k] * B[k][j]; } } }
这里我们的 \(q\)
被制约,导致程序性能落入了
bandwidth bound,即由于程序的内存利用率低下,带宽制约了程序的性能提升。解决方案有两个:升级硬件并提升带宽,增加计算强度上限
(\(q\) )
从运行时间预测公式也可以得出相同结论: \[
predicted \ time = ft_f (1 + \frac{t_m}{t_f}\times \frac{1}{q})
\]
\(t_m\)
是传递一个单位的数据耗时\(t_f\) 是一个计算操作的耗时\(f\) 是计算操作的数量\(ft_f\) 是性能峰值
Blocked GEMM
数据传输 Naive vs Outer vs Inner product (非方阵情况 m, n,
k):
对 m 分了 M 块,对 n 分了 N 块,对 k 分了 K 块
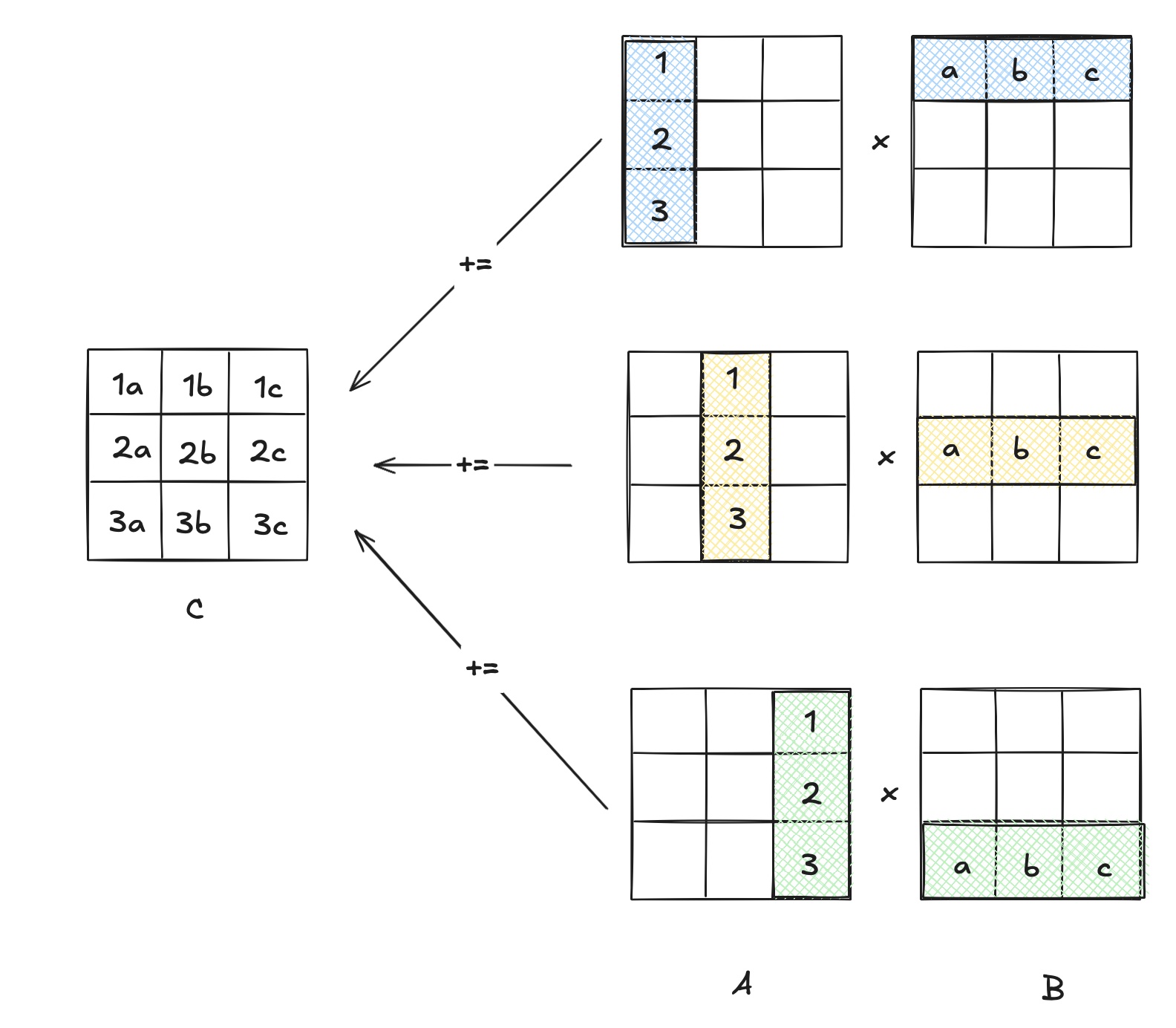
C
\(2mn / L\) \(2mn / L\) \(2Kmn / L\)
A
\(mk / L\) \(Nmk / L\) \(mk / L\)
B
\(mkn / L\) \(Mnk/L\) \(Mnk / L\)
在三种实现的数据传输中,内积和外积在传输操作数上对naive实现有数量级上的优势。对比inner
product 和 outer product, 不难发现inner product 在传输 C
所用的操作较少,传输 A 时用的操作较多。我们可以根据实际矩阵乘法的 C 和 A
的大小来决定使用inner product 还是 Outer product。
性能分析:
我们希望 \(q\)
尽可能大,根据公式,我们无法调节问题规模 \(n\) , 只能尽量调小 \(N\) ,
即把子矩阵分割的更大,让块的数量更小。然而在实际实现中,我们还需要考虑缓存的大小。如果将子矩阵分割太大导致其无法被装进缓存里,这将大大降低其性能。因此我们应尽量让找到一个子矩阵大小的临界值并将其设为N。
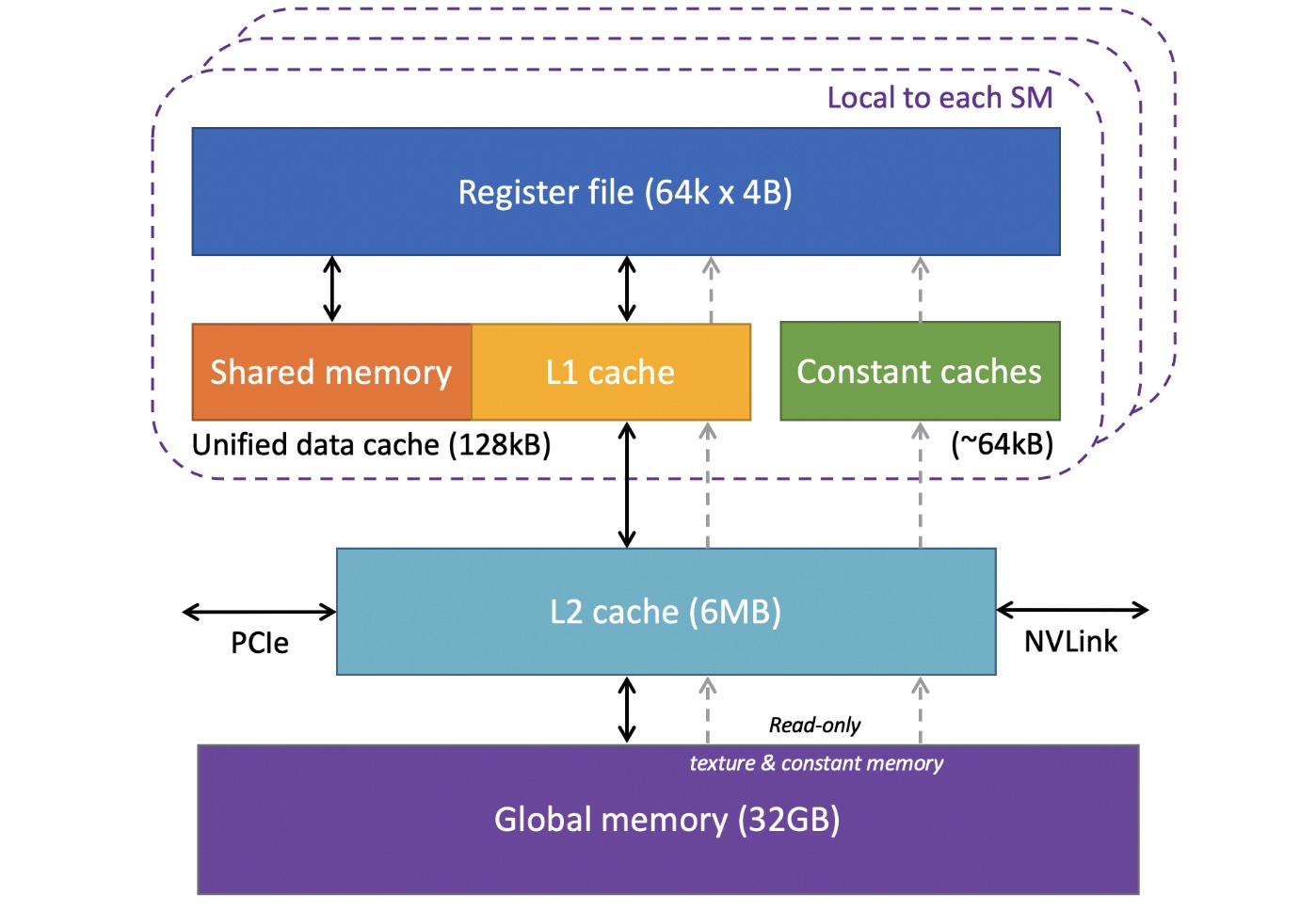
假设 \(M_{fast}\) 是快速存储空间
(\(L1\) 或 \(L1 + L2\) ),我们希望将 \(A\) , \(B\) , 和 \(C\) 放入 \(M_{fast}\) 中。因此 \(N\) 必须大于 \(n
\times (3/M_{fast})^{\frac{1}{2}}\) 。因为我们想要 \(N\) 越小越好,从而最大化 \(q\) 。因此,如果我们能正确使用 \(M_{fast}\) : \[
q = \frac{2n^3}{(2(n(\frac{3}{M_{fast}})^{\frac{1}{2}}) + 2) \times
n^2/L} \approx L\times (M_{fast} / 3)^{1/2}
\] 这是通过内积公式推导的,外积公式只有常量改变,推导出的 \(q\)
性能公式与内积推导出的相同。从这个公式我们发现 \(q\) 只与 \(M_{fast}\) 有关。回忆
predicted time 的计算公式 \[
predict \ time = ft_{f} (1 + (\frac{1}{\frac{t_f}{t_m}})(\frac{1}{q}))
\] 我们可以计算出想要达到理论性能峰值的百分比至少需要多大的缓存
(lower bound)。假设我们想要达到理论性能峰值的50%: \[
predicted \ time = ft_f \times 2 \\
that \ is: \ \ \ (\frac{1}{\frac{t_f}{t_m}})(\frac{1}{q}) = 1 \\
then: \ \ \ \ \ q = \frac{t_m}{t_f} \\
\text{We know:} \ \ \ q \approx L(M_{fast} / 3)^{1/2} \\
M_{fast} = 3 \times (t_m / (Lt_f))^2
\] 至此我们算出加入我们想让性能达到理论峰值的50%,我们至少要让
\(M_{fast}\)
达到这个数值。注意:这个公式只表示理论下限,实际上 \(M_{fast}\) 应该要更大些。
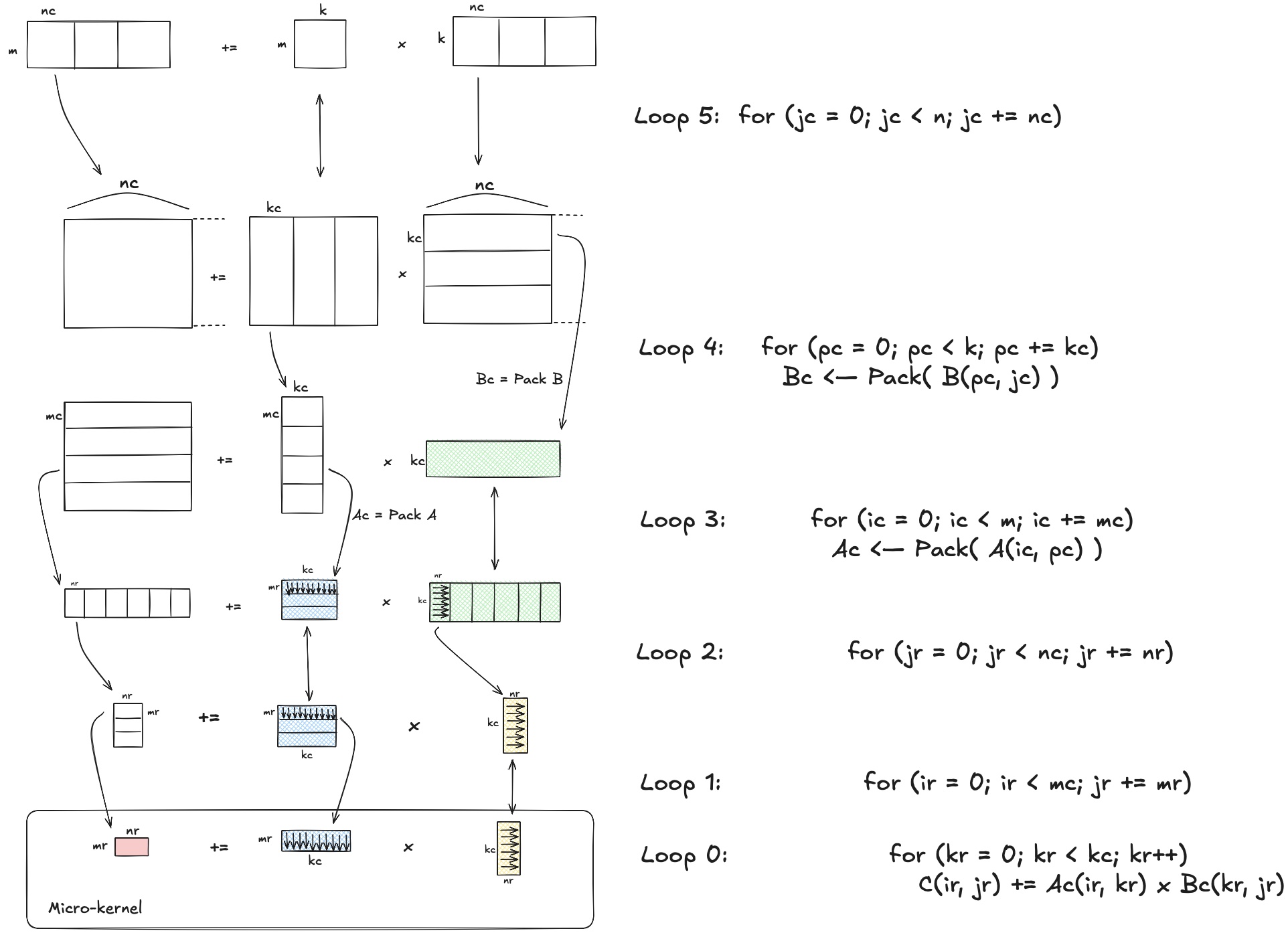
最大限度使用分层缓存:BLIS框架
BLIS框架 的主要特点是优化矩阵乘法的计算过程,使计算能最大化利用CPU的多级缓存(L1、L2、L3)。特别是BLIS框架通过将复杂计算分解为一个需要高度优化的小型内核(micro-kernel),显著降低了需要直接优化的代码量。
这里BLIS框架把数据分成了多个块,在块中的数据也被划分到了更小的块。这样的划分可以让程序:
将小块数据存储在L1缓存中,供微内核重复使用。
将矩阵更大块存储在L2缓存中,可以通过分块降低数据传输的延迟。
将大块数据驻留在其L3,供多个L2块复用。
在上述程序中,A的块 \((mr, kc)\)
被保存在 L2 缓存中,降低访问延迟。B的块 \((kc,
nr)\) 被保存在 L1 缓存中,他将被 A 的块重复使用。
注意:我们无法显式的将某段数据存放在某一个缓存层中,数据被放置在哪由它的出现频率决定
(缓存调度规则也有影响)。我们说 B 的块被缓存在 L1 中是因为 B
块中相同数据出现频率比较高。根据缓存调度规则,我们认为这部分数据会被”尽可能地“存储在L1中。
分块的本质是为了给用户提供可调节的参数,让应该在L1中的数据不出现在L2,应该出现在
L2 的数据不出现在 L3。
我们在做分块的时候还可以根据情况做 Packing,packing 将
\(A\) 和 \(B\)
中需要连续访问的数据重新排序使之存放在连续的内存空间中。这样做 CPU
在访问内存时,可以高效使用cacheLine,同时 cache
内存储的都是需要被使用的数据,将conflict miss降到最低。
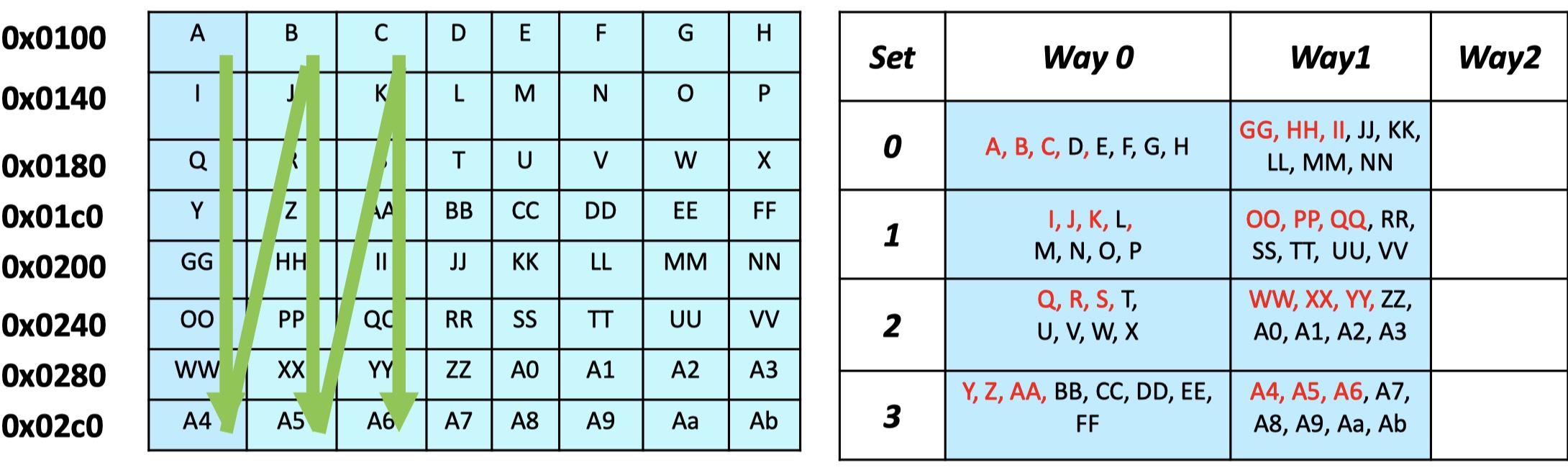
这里是一个没有packing过的数据,缓存行大小 = 64 bytes,8 bytes /
element。我们可以算出一个缓存行会抓取 8
个element。因此右图是数据在缓存中的存储方式。我们可以发现在一个缓存块中我们当前需要的元素只占一小部分。这会导致缓存利用率较低。即便我们可能会在后续使用
"D E F G H ...", 我们无法保证这个缓存块不会被替换因为 way
也是有限的,也就是会发生 conflict miss。
提升Micro-Kernel性能:SIMD
SIMD 是CPU层面的加速,有特定硬件支持。
1 2 MMX, SSE[1:5], AVX: x86 NEON, SVE: ARM
以SVE为例,支持SVE得架构提供了32个可伸缩向量寄存器,16个可伸缩的Predicate寄存器等等。
可伸缩向量寄存器:可存储一个向量的数据 (支持64, 32, 16, 8位 &
单精度 & 双精度)
可伸缩 Predicate 寄存器: 控制哪些元素参与计算
\[
\mathbf{C} =
\begin{bmatrix}
c_{11} & c_{12} \\
c_{21} & c_{22}
\end{bmatrix}
=
\begin{bmatrix}
a_{11} & a_{12} \\
a_{21} & a_{22}
\end{bmatrix}
\cdot
\begin{bmatrix}
b_{11} & b_{12} \\
b_{21} & b_{22}
\end{bmatrix}
\]
用SIMD实现: \[
<c_{11}, c_{21}> \text{+=} <a_{11}, a_{11}> · <b_{11},
b_{12}>
\] \[
<c_{11}, c_{21}> \text{+=} <a_{12}, a_{12}> · <b_{21},
b_{22}>
\] \[
<c_{12}, c_{22}> \text{+=} <a_{11}, a_{21}> · <b_{12},
b_{12}>
\] \[
<c_{12}, c_{22}> \text{+=} <a_{12}, a_{22}> · <b_{22},
b_{22}>\\
\]
1 2 3 4 5 6 7 register svfloat64_t a; veca = svldl (pred, A + i); svst1_f64 (pred, C+i, vecc); svwhilelt_b64 (i, N); svptest_any (svptrue_b64 (), pred); svdup_f64 (aval); svmla_f64_m (npred, c0x, bx, ax);
向量和predicate的组织结构:
访存优化:
Alignment (数据对齐)
数据对齐的要求是不同对象在内存中存放的位置为 \(2^n\) 的倍数 (\(n\) 根据数据类型而不同,Linux
对short类型要求是2的倍数,对int,
double这种要求是4的倍数)。数据对齐的意义:一个处理器通常能从内存读取一个缓存行的数据。如果数据未对齐,可能会跨越两个缓存行
(Cache Line Crossing),
导致性能损失。同时,如果数据访问跨越内存页面边界,可能需要额外的地址转换操作
(TLB Miss)。
Handling of Stores
(存储操作处理)
流式存储指令 (Streaming Store Intructions)
存储时直接写回到内存,不会分配到缓存,适用于不太可能被重用/无法装入缓存的数据,同时避免了缓存污染
写合并 (Write Combining)
如果硬件支持写合并,会有一个写合并缓冲区 (Write Combining
Region),存储小的写入合并,并将他们合并成一个较大的事务。注意:写合并以来连续内存区域,因此数据必须对齐。写合并最适用于流式访存。
提高指令并行度: Loop Unroll
Loop Unroll
让在一个循环中让更多的寄存器被使用。在unroll后,可以让计算和加载交替进行,增加了指令并行性
(指令流水线),促进CPU进行指令流水线优化。由于向量寄存器存在上限,如果使用寄存器超过上限便要进行压栈操作,从而降低性能。
pa1_result2.jpg
附: Butterfly Method -
理论王者
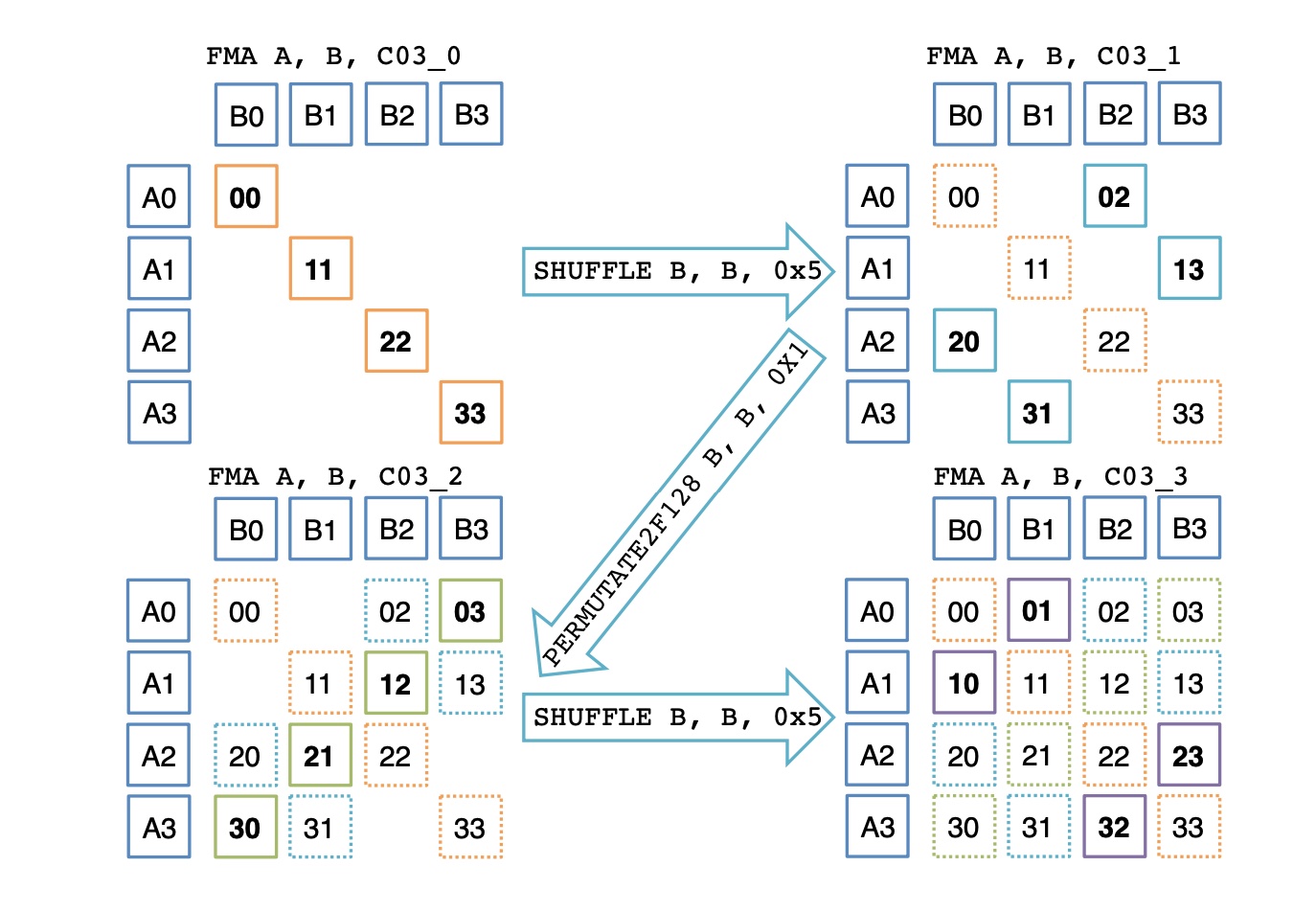
理论上butterfly Method
避免了广播,操作更少,小于应该更高。但我们目前实现的效果并不好.
初始值:[\(A_0\) , \(A_1\) , \(A_2\) , \(A_3\) ], [\(B_0\) , \(B_1\) , \(B_2\) , \(B_3\) ]
对 \(B\)
交换前半部分和后半部分:[\(A_0\) , \(A_1\) , \(A_2\) , \(A_3\) ], [\(B_2\) , \(B_3\) , \(B_0\) , \(B_1\) ]
对 \(B\)
前半部分和后半部分分别内部交换:[\(A_0\) , \(A_1\) , \(A_2\) , \(A_3\) ], [\(B_3\) , \(B_2\) , \(B_1\) , \(B_0\) ]
对 \(B\)
交换前半部分和后半部分:[\(A_0\) , \(A_1\) , \(A_2\) , \(A_3\) ], [\(B_1\) , \(B_0\) , \(B_3\) , \(B_2\) ]
此时 \(C\)
的所有结果都已经算出来了,但是乱序的 (如图)。
重新排序 (12 instructions):
Reference
https://arxiv.org/pdf/1609.00076